Web开发是一项无聊而且单调的工作 , 特别是在视图功能编写方面更为显著 .
为了减少这种痛苦 , Django植入了视图类这一功能 , 该功能封装了视图开发常用的代码 ,
无须编写大量代码即可快速完成数据视图的开发 , 这种以类的形式实现响应与请求处理称为CBV ( Class Base Views ) .
视图类是通过定义和声明类的形式实现的 , 根据用途划分 3 部分 : 数据显示视图 , 数据操作视图和日期筛选视图 .
数据显示视图是将后台的数据展示在网页上 , 数据主要来自模型 , 一共定义了 4 个视图类 ,
分别是RedirectView , TemplateView , ListView和DetailView , 说明如下 :
● RedirectView用于实现HTTP重定向 , 默认情况下只定义GET请求的处理方法 .
● TemplateView是视图类的基础视图 , 可将数据传递给HTML模板 , 默认情况下只定义GET请求的处理方法 .
● ListView是在TemplateView的基础上将数据以列表显示 , 通常将某个数据表的数据以列表表示 .
● DetailView是在TemplateView的基础上将数据详细显示 , 通常获取数据表的单条数据 .
在 3.3 .3 小节已简单演示了视图类RedirectView的使用方法 , 本小节将深入了解视图类RedirectView .
视图类RedirectView用于实现HTTP重定向功能 , 即网页跳转功能 .
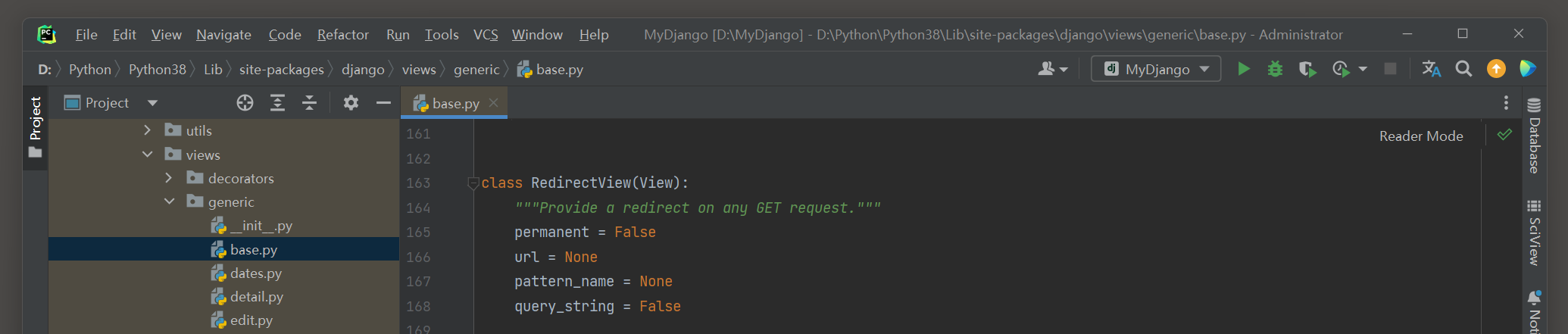
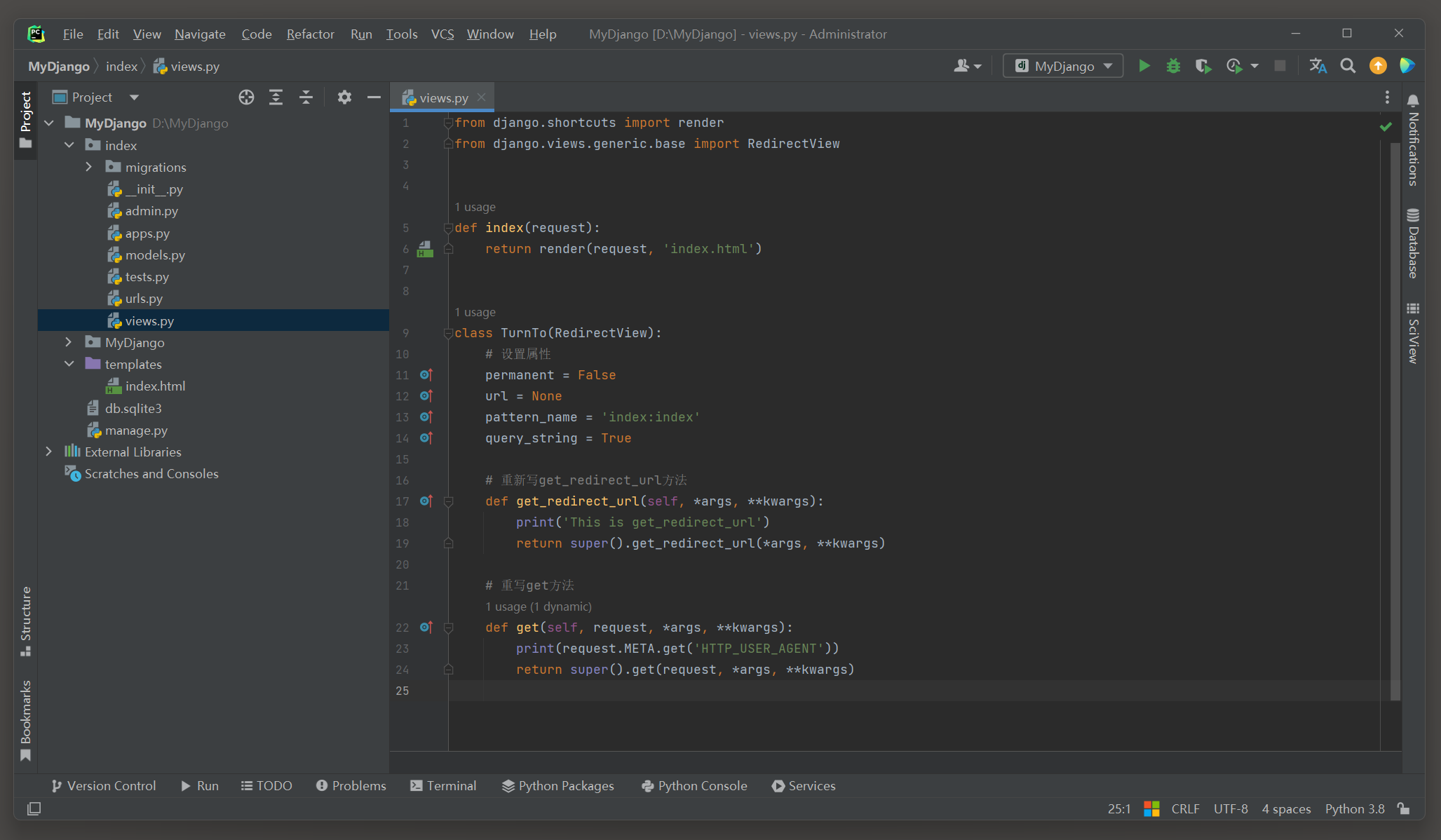
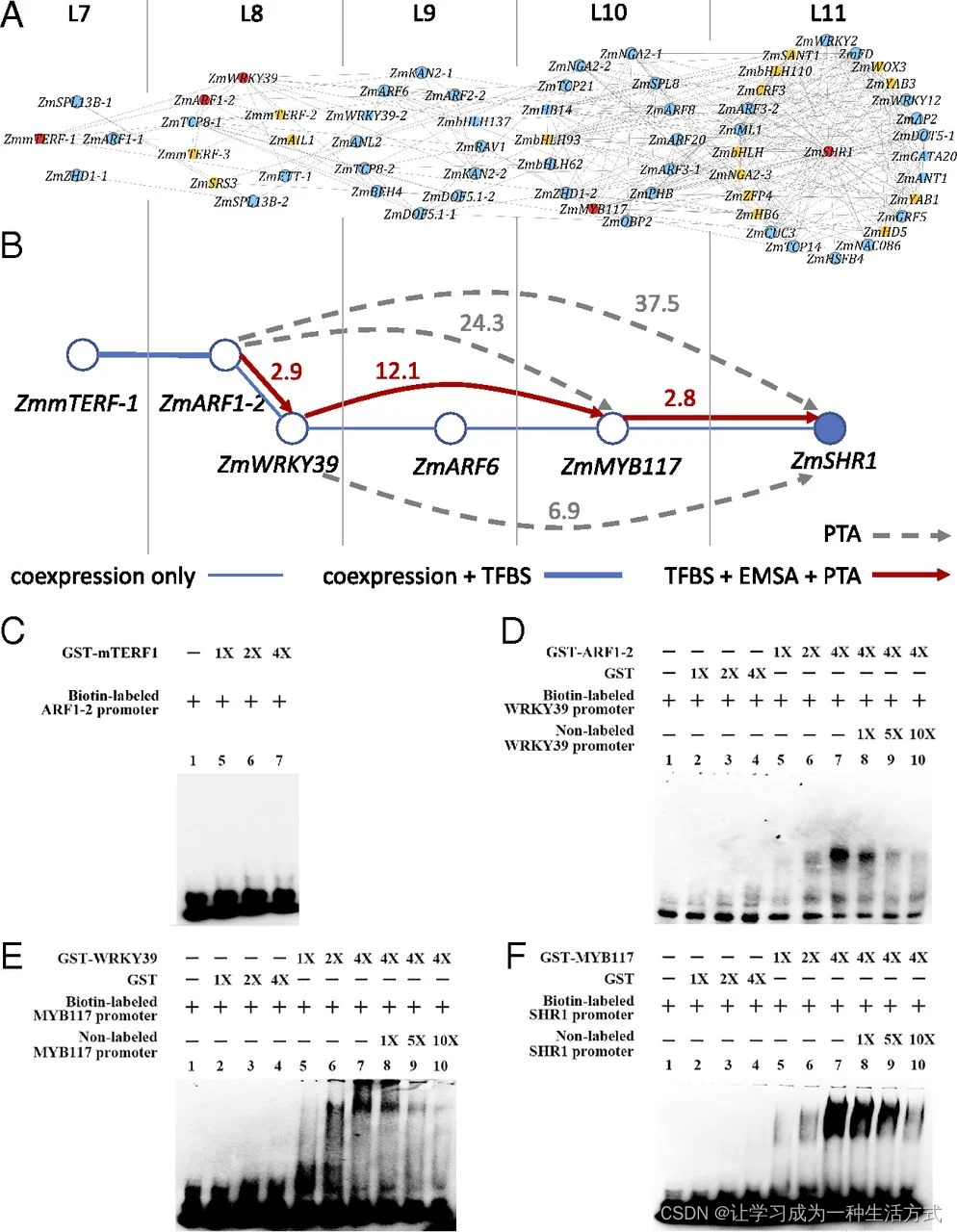
在Django的源码里可以看到视图类RedirectView的定义过程 , 如图 5 - 1 所示 .
图 5 - 1 视图类RedirectView
从图 5 - 1 得知 , 视图类RedirectView继承父类View , 类View是所有视图类的底层功能类 .
视图类RedirectView定义了 4 个属性和 8 个类方法 , 分别说明如下 :
● permanent : 根据属性值的真假来选择重定向方式 , 若为True , 则HTTP状态码为 301 , 否则HTTP状态码为 302 ( 临时重定向 ) .
● url : 代表重定向的路由地址 .
● pattern_name : 代表重定向的路由命名 . 如果已设置参数url , 则无须设置该参数 , 否则提示异常信息 .
● query_string : 是否将当前路由地址的请求参数传递到重定向的路由地址 .
● get_redirect_url ( ) : 根据属性pattern_name所指向的路由命名来生成相应的路由地址 .
● get ( ) : 触发HTTP的GET请求所执行的响应处理 .
● 剩余的类方法head ( ) , post ( ) , options ( ) , delete ( ) , put ( ) 和patch ( ) 是HTTP的不同请求方式 , 它们都由get ( ) 方法完成响应处理 .
在 3.3 .3 小节 , 视图类RedirectView是在urls . py文件里直接使用的 , 由于类具有继承的特性 ,
因此还可以对视图类RedirectView进行功能扩展 , 这样能满足复杂的开发需求 .
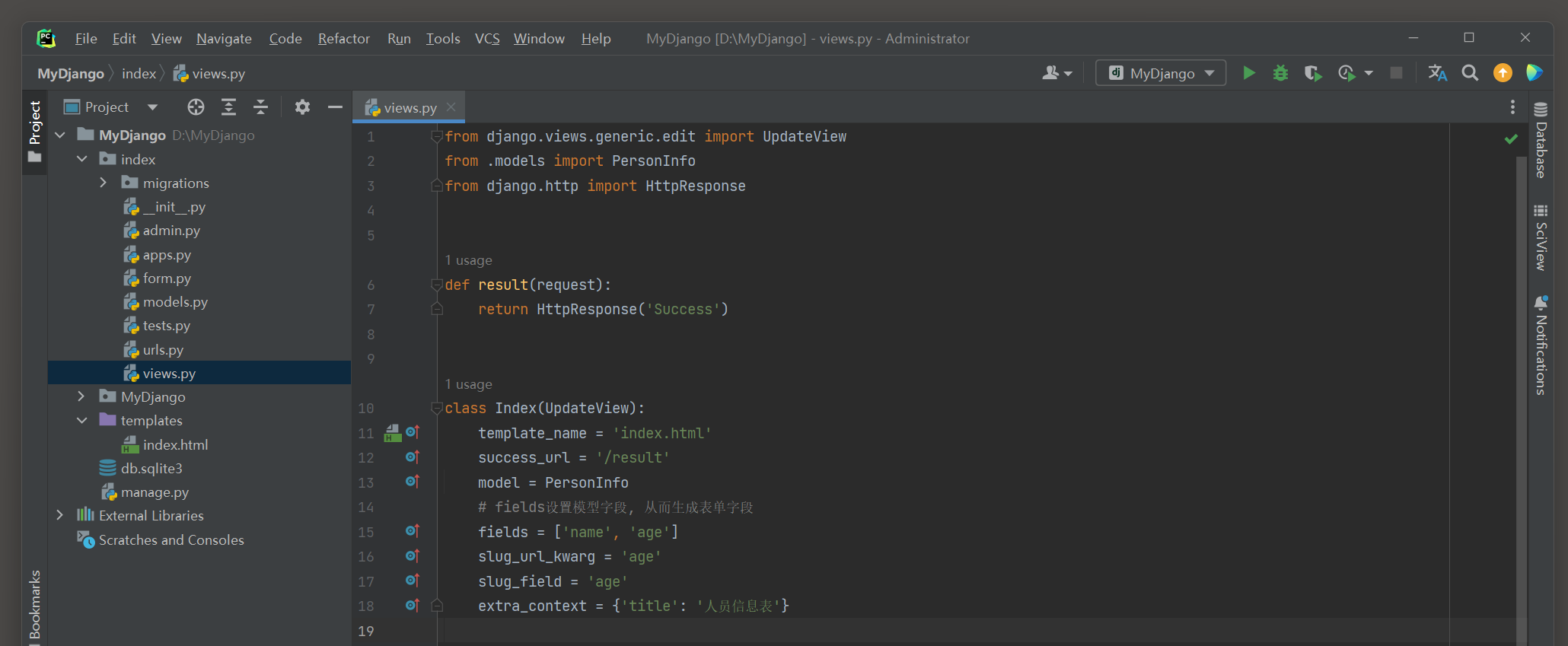
以MyDjango为例 , 在index的urls . py , views . py和模板文件index . html中编写以下代码 :
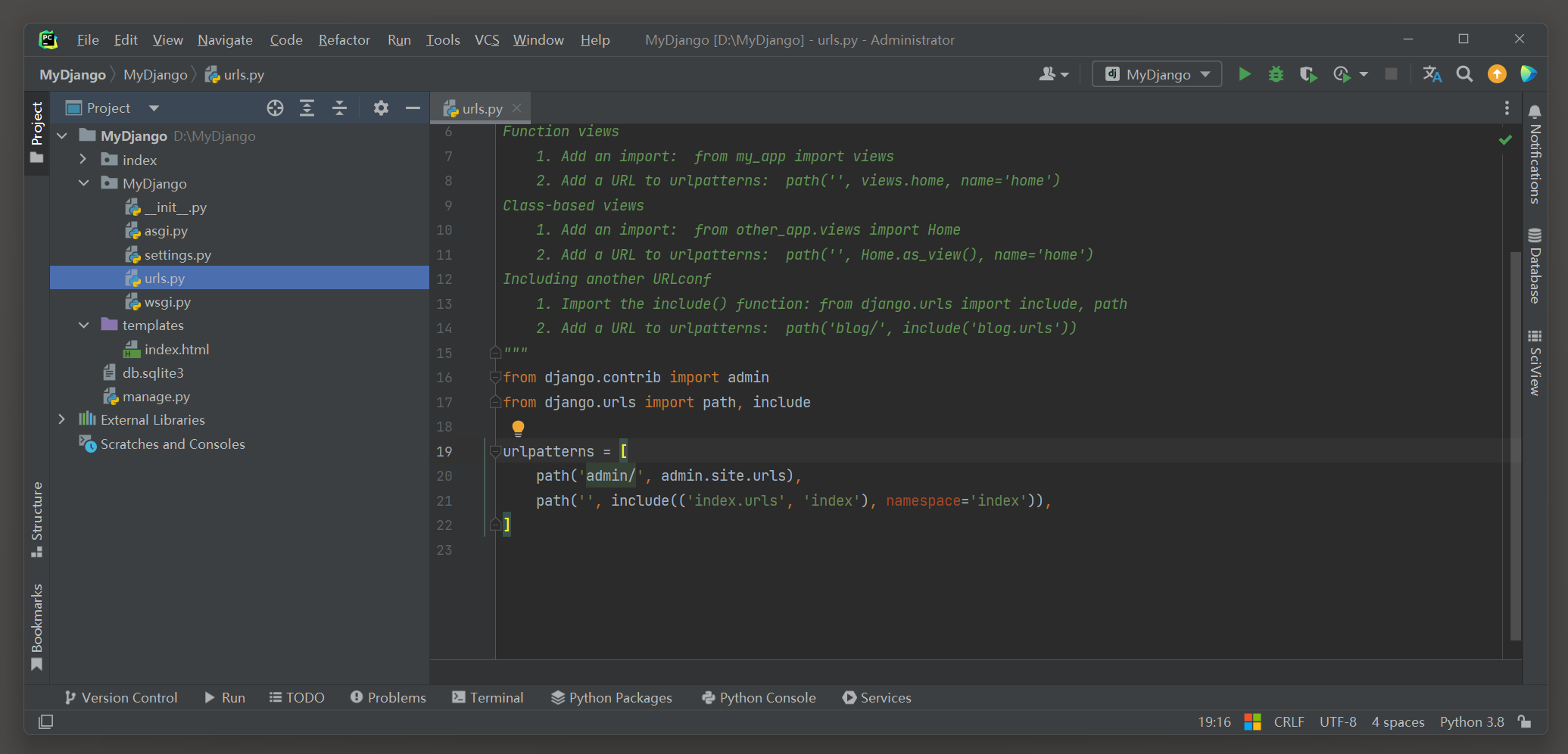
from django. contrib import admin
from django. urls import path, include
urlpatterns = [
path( 'admin/' , admin. site. urls) ,
path( '' , include( ( 'index.urls' , 'index' ) , namespace= 'index' ) ) ,
]
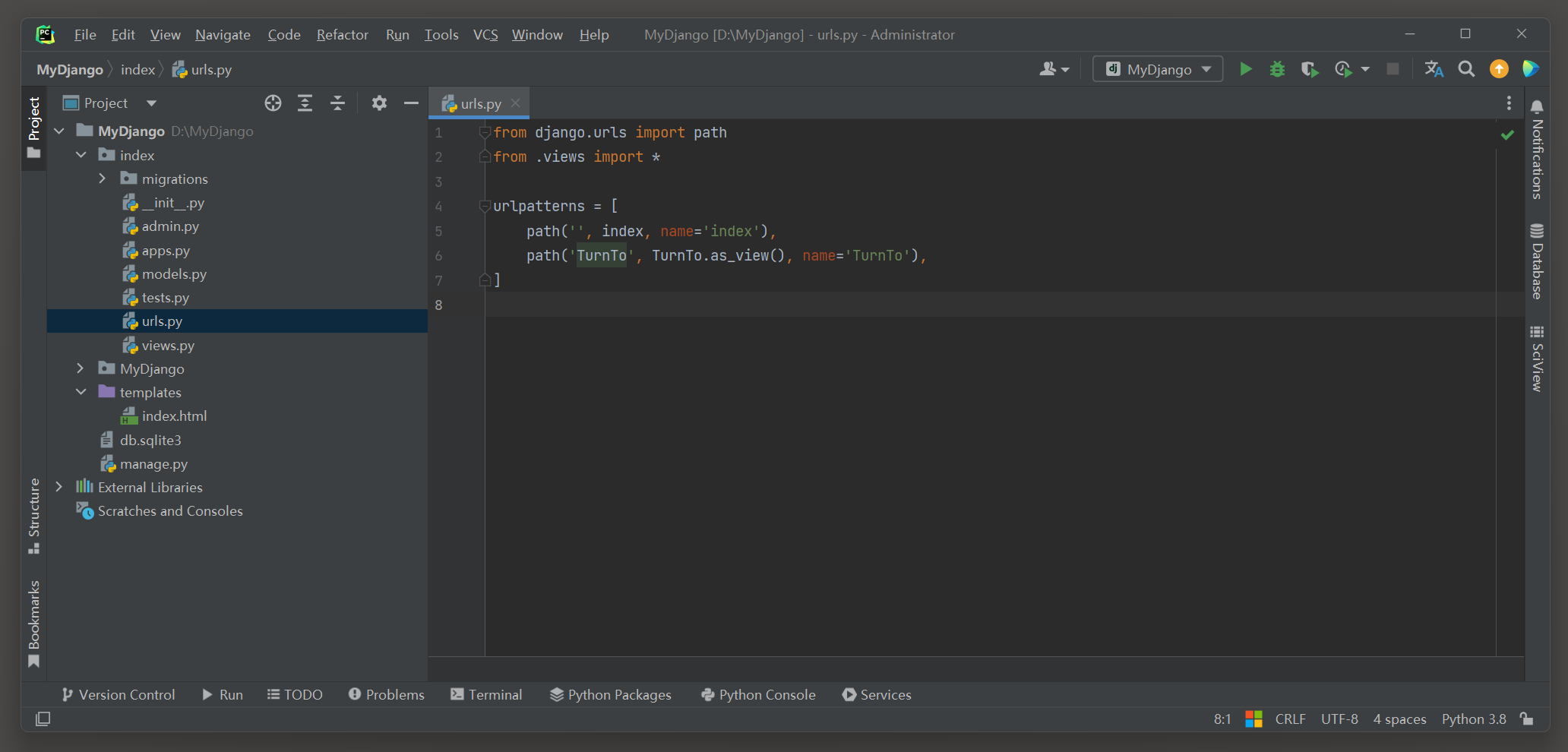
from django. urls import path
from . views import *
urlpatterns = [
path( '' , index, name= 'index' ) ,
path( 'TurnTo' , TurnTo. as_view( ) , name= 'TurnTo' ) ,
]
from django. shortcuts import render
from django. views. generic. base import RedirectView
def index ( request) :
return render( request, 'index.html' )
class TurnTo ( RedirectView) :
permanent = False
url = None
pattern_name = 'index:index'
query_string = True
def get_redirect_url ( self, * args, ** kwargs) :
print ( 'This is get_redirect_url' )
return super ( ) . get_redirect_url( * args, ** kwargs)
def get ( self, request, * args, ** kwargs) :
print ( request. META. get( 'HTTP_USER_AGENT' ) )
return super ( ) . get( request, * args, ** kwargs)
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h3> </ h3> < ahref = " {% url 'index:TurnTo' %}?k=1" > </ a> </ body> </ html>
在index的views . py中定义了视图类TurnTo , 它继承父类RedirectView ,
对父类的属性进行重设并将父类的类方法get_redirect_url ( ) 和get ( ) 进行重写 ,
通过这样的方式可以对视图类RedirectView进行功能扩展 , 从而满足开发需求 .
定义路由的时候 , 若使用视图类TurnTo处理HTTP请求 ,
则需要对视图类TurnTo使用as_view ( ) 方法 , 这是对视图类turnTo进行实例化处理 .
as_view ( ) 方法可在类View里找到具体的定义过程 ( django \ views \ generic \ base . py ) .
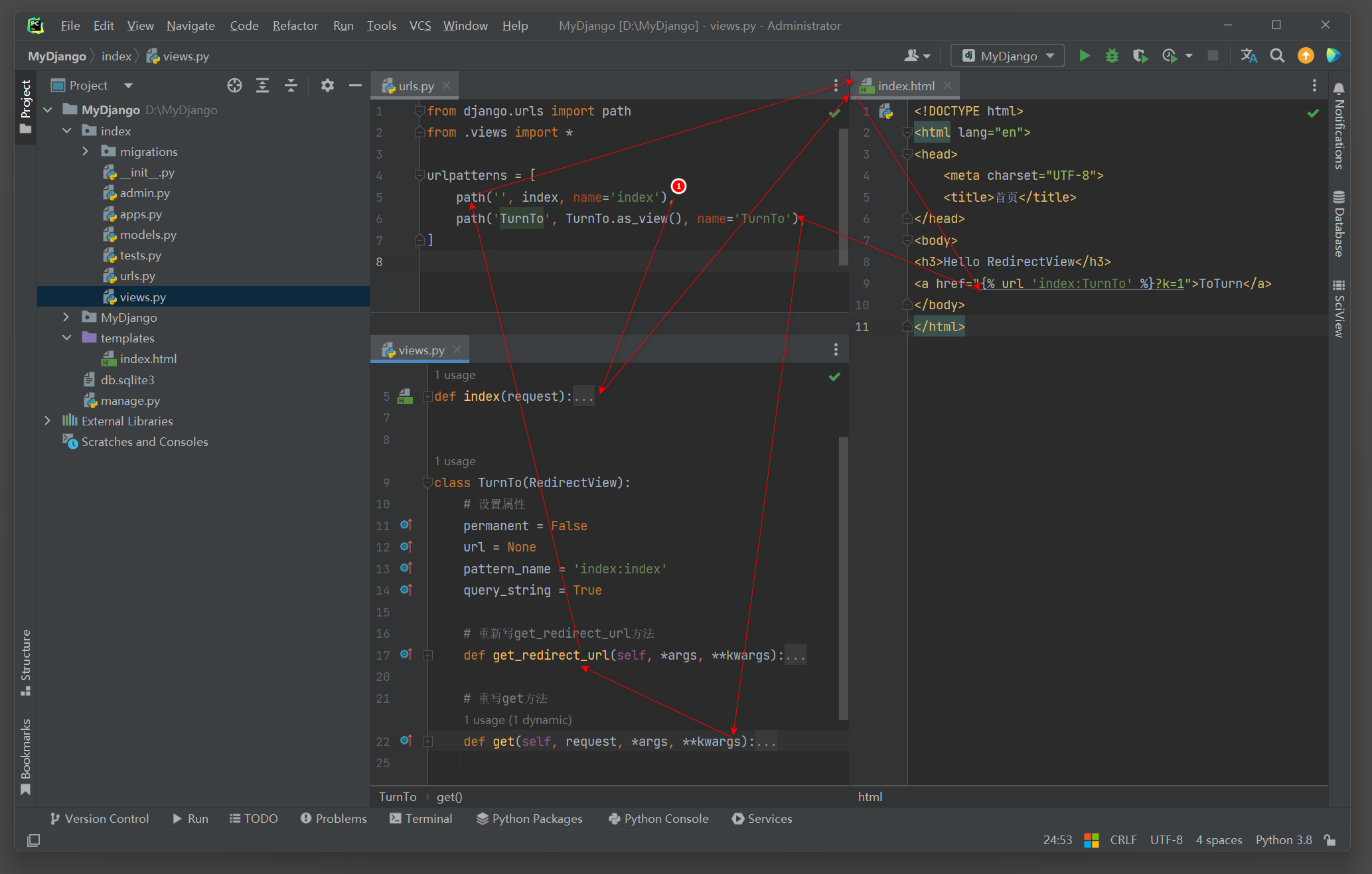
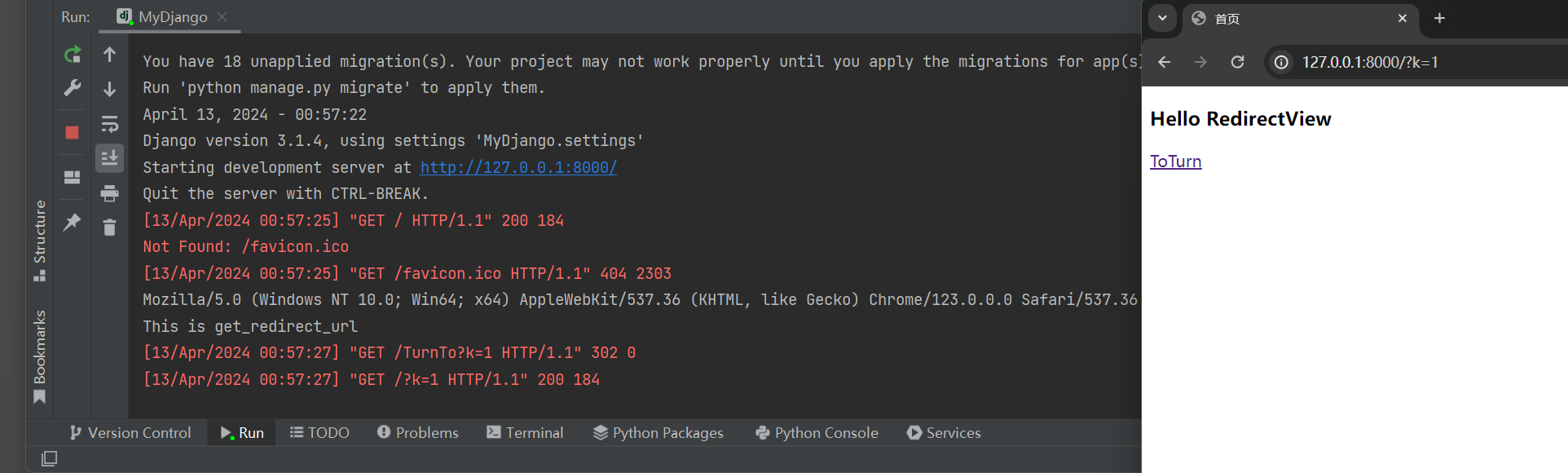
运行MyDjango项目 , 在浏览器上访问 127.0 .0 .1 : 8000 , 当单击 'ToTurn' 链接后 ,
浏览器的地址栏将会变为 : 127.0 .0 .1 : 8000 /?k= 1 , 在PyCharm里可以看到视图类TurnTo的输出内容 , 如图 5 - 2 所示 .
( 当你访问与TurnTo视图关联的URL时 , get方法首先执行 , 然后在get方法内部会调用get_redirect_url方法来获取重定向的URL . )
( 客户端向 / TurnTo?k = 1 发起了一个GET请求 , 服务器返回了一个 302 状态码 , 并可能在响应头中包含了Location : / ?k = 1 这样的信息 .
然后 , 客户端遵循这个重定向 , 向新的URL / ?k = 1 发起了一个新的GET请求 , 这次请求返回了 200 状态码 , 表示请求成功 . )
图 5 - 2 视图类TurnTo的输出内容
上述例子只是重写了GET请求的响应处理 , 如果在开发过程中需要对其他的HTTP请求进行处理 ,
那么只要重新定义相应的类方法即可 , 比如在视图类TurnTo里定义类方法post ( ) , 该方法是定义POST请求的响应过程 .
客户端向 / TurnTo?k = 1 发起了一个GET请求 , 服务器返回了一个 302 状态码 , 并可能在响应头中包含了Location : / ?k = 1 这样的信息 .
然后 , 客户端遵循这个重定向 , 向新的URL / ?k = 1 发起了一个新的GET请求 , 这次请求返回了 200 状态码 , 表示请求成功 .
视图类TemplateView是所有视图类里最基础的应用视图类 ,
开发者可以直接调用应用视图类 , 它继承多个父类 : TemplateResponseMixin , ContextMixin和View .
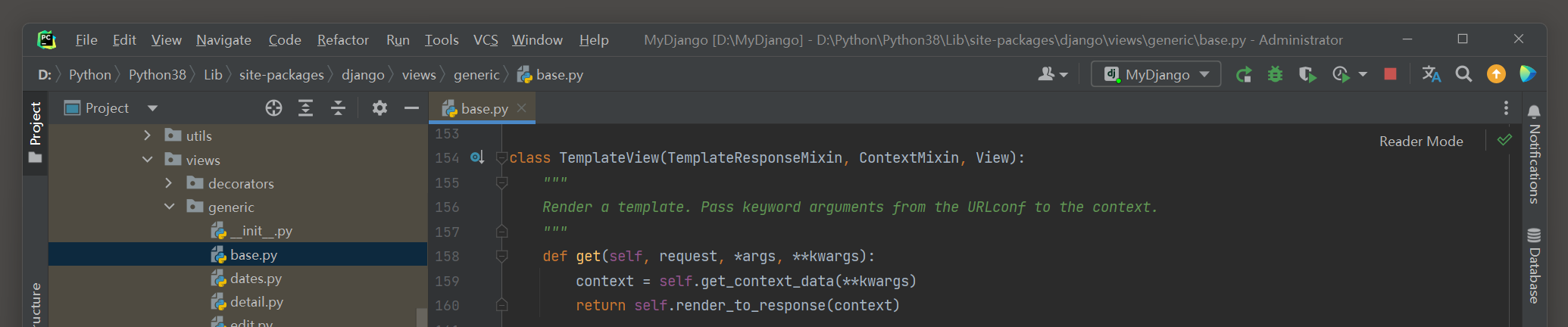
在PyCharm里查看视图类TemplateView的源码 , 如图 5 - 3 所示 .
图 5 - 3 视图类TemplateView的源码
从视图类TemplateView的源码看到 , 它只定义了类方法get ( ) ,
该方法分别调用函数方法get_context_data ( ) 和render_to_response ( ) , 从而完成HTTP请求的响应过程 .
类方法get ( ) 所调用的函数方法主要来自父类TemplateResponseMixin和ContextMixin ,
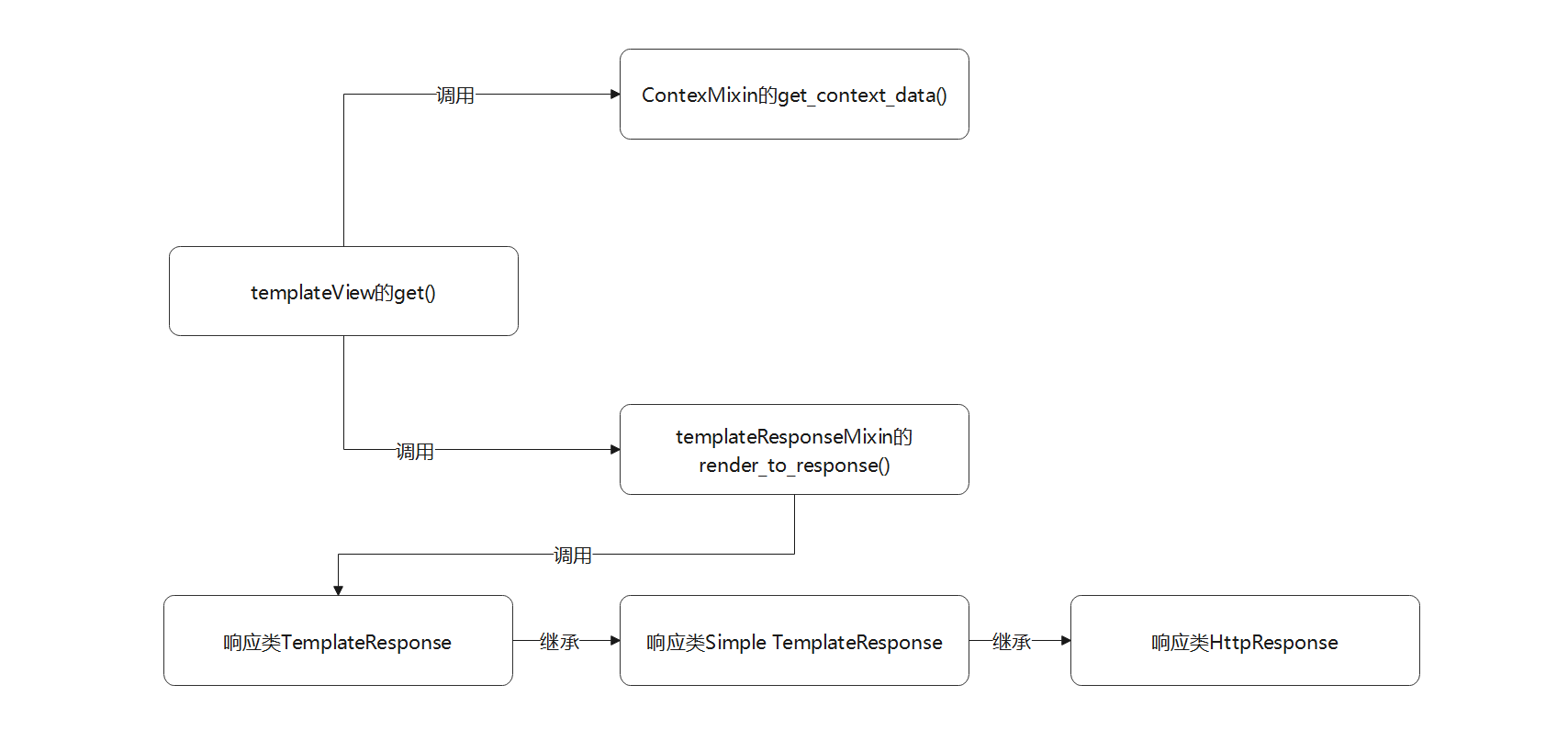
为了准确地描述函数方法的调用过程 , 我们以流程图的形式加以说明 , 如图 5 - 4 所示 .
图 5 - 4 视图类TemplateView的定义过程
视图类TemplateView的get ( ) 所调用的函数说明如下:
● 视图类ContextMixin的get_context_data ( ) 方法用于获取模板上下文内容 ,
模板上下文是将视图里的数据传递到模板文件 , 再由模板引擎将数据转换成HTML网页数据 .
● 视图类TemplateResponseMixin的render_to_response ( ) 用于实现响应处理 , 由响应类TemplateResponse完成 .
我们可以在视图类TemplateView的源码文件里找到视图类TemplateResponseMixin的定义过程 ,
该类设置了 4 个属性和两个类方法 , 这些属性和类方法说明如下 :
● template_name : 设置模板文件的文件名 .
● template_engine : 设置解析模板文件的模板引擎 .
● response_class : 设置HTTP请求的响应类 , 默认值为响应类TemplateResponse .
● content_type : 设置响应内容的数据格式 , 一般情况下使用默认值即可 .
● render_to_response ( ) : 实现响应处理 , 由响应类TemplateResponse完成 .
● get_template_names ( ) : 获取属性template_name的值 .
经上分析 , 我们已对视图类TemplateView有了一定的了解 ,
现在通过简单的例子讲述如何使用视图类TemplateView实现视图功能 , 完成HTTP的请求与响应处理 .
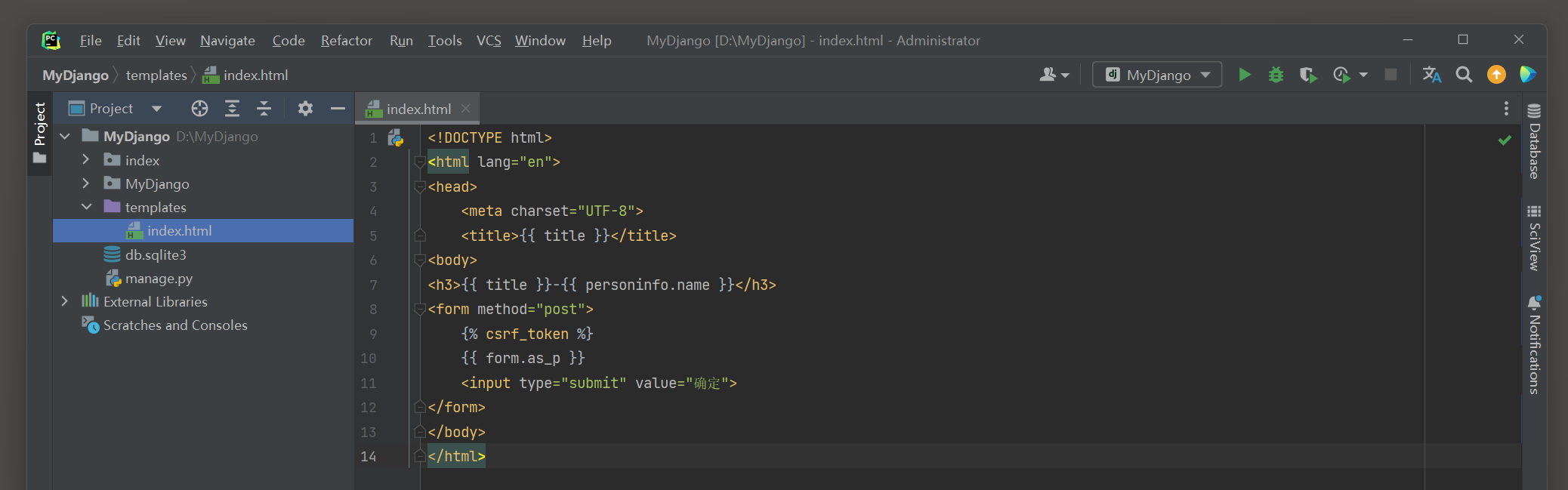
以MyDjango为例 , 在index的urls . py , views . py和模板文件index . html中编写以下代码 :
from django. urls import path
from . views import *
urlpatterns = [
path( '' , Index. as_view( ) , name= 'index' ) ,
]
from django. views. generic. base import TemplateView
class Index ( TemplateView) :
template_name = 'index.html'
template_engine = None
content_type = None
extra_context = { 'title' : 'This is GET' }
def get_context_data ( self, ** kwargs) :
context = super ( ) . get_context_data( ** kwargs)
context[ 'value' ] = 'I am MyDjango'
return context
def post ( self, request, * args, ** kwargs) :
self. extra_context = { 'title' : 'This is POST' }
context = self. get_context_data( ** kwargs)
return self. render_to_response( context)
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h3> </ h3> < div> </ div> < br> < formaction = " " method = " post" > < inputtype = " submit" value = " submit" > </ form> </ body> </ html> 上述代码是将网站首页的视图函数index改为视图类index ,
自定义视图类index继承视图类TemplateView , 并重设了 4 个属性 , 重写了两个类方法 , 具体说明如下 :
● template_name : 将模板文件index . html作为网页文件 .
● template_engine : 设置解析模板文件的模板引擎 , 默认值为None ,
即默认使用配置文件settings . py的TEMPLATES所设置的模板引擎BACKEND .
● content_type : 设置响应内容的数据格式 , 默认值为None , 即代表数据格式为text / html .
● extra_context : 为模板文件的上下文 ( 模板变量 ) 设置变量值 , 可将数据转换成网页数据展示在浏览器上 .
● get_context_data ( ) : 继承并重写视图类TemplateView的类方法 , 在变量context里新增数据value .
● post ( ) : 自定义POST请求的处理方法 , 当触发POST请求时 , 将会重设属性extra_context的值 ,
并调用get_context_data ( ) 将属性extra_context重新写入 , 从而实现动态改变模板上下文的数据内容 .
在模板文件index . html里看到模板上下文 ( 模板变量 ) { { title } } 和 { { value } } , 它们的数据来源于get_context_data ( ) 的返回值 .
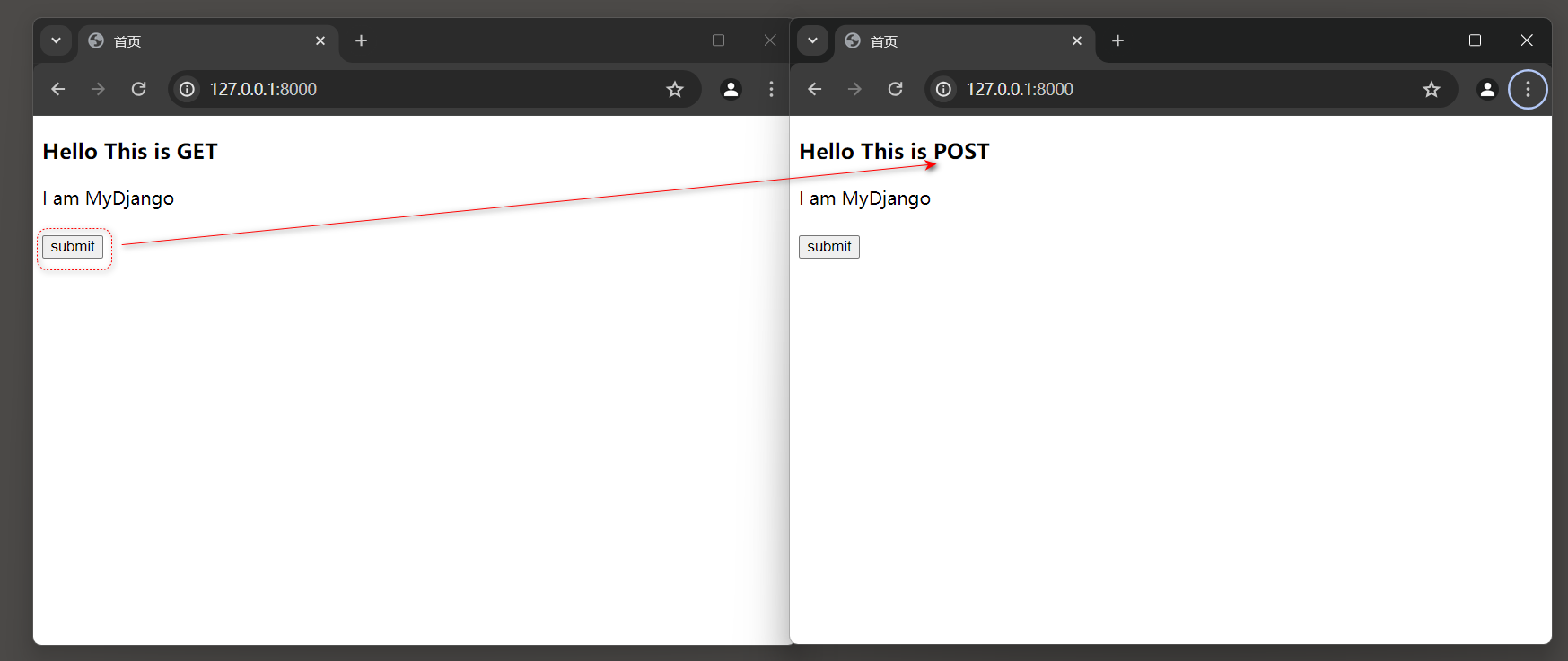
当访问 : 127.0 .0 .1 : 8000 的时候 , 上下文title为 'This is GET' ;
当单击 'submit' 按钮的时候 , 上下文title的值改为 'This is POST' , 如图 5 - 5 所示 .
图 5 - 5 运行结果
( context和extra_context是两个与模板渲染时使用的上下文 ( context ) 相关的概念 .
context是一个字典 , 它包含了传递给模板的所有变量 . 在TemplateView或其子类中 ,
通常会重写get_context_data方法来定制传递给模板的上下文 .
这个方法的默认实现是从视图中的其他属性和传入的 * * kwargs 中获取数据 , 然后返回一个字典 .
extra_context是TemplateView类的一个属性 , 它是一个字典 , 用于存储要添加到模板上下文中的额外变量 .
这些变量会在get_context_data方法中被合并到最终的上下文字典中 .
extra_context用于定义视图类级别的默认上下文变量 , 而context则用于在每个请求处理过程中动态构建和定制上下文 . )
我们知道视图是连接路由和模板的中心枢纽 , 除此之外 , 视图还可以连接模型 .
简单来说 , 模型是指Django通过一定的规则来映射数据库 ,
从而方便Django与数据库之间实现数据交互 , 这个交互过程是在视图里实现的 .
由于视图可以与数据库实现数据交互 , 因此Django定义了视图类ListView ,
该视图类是将数据表的数据以列表的形式显示 , 常用于数据的查询和展示 .
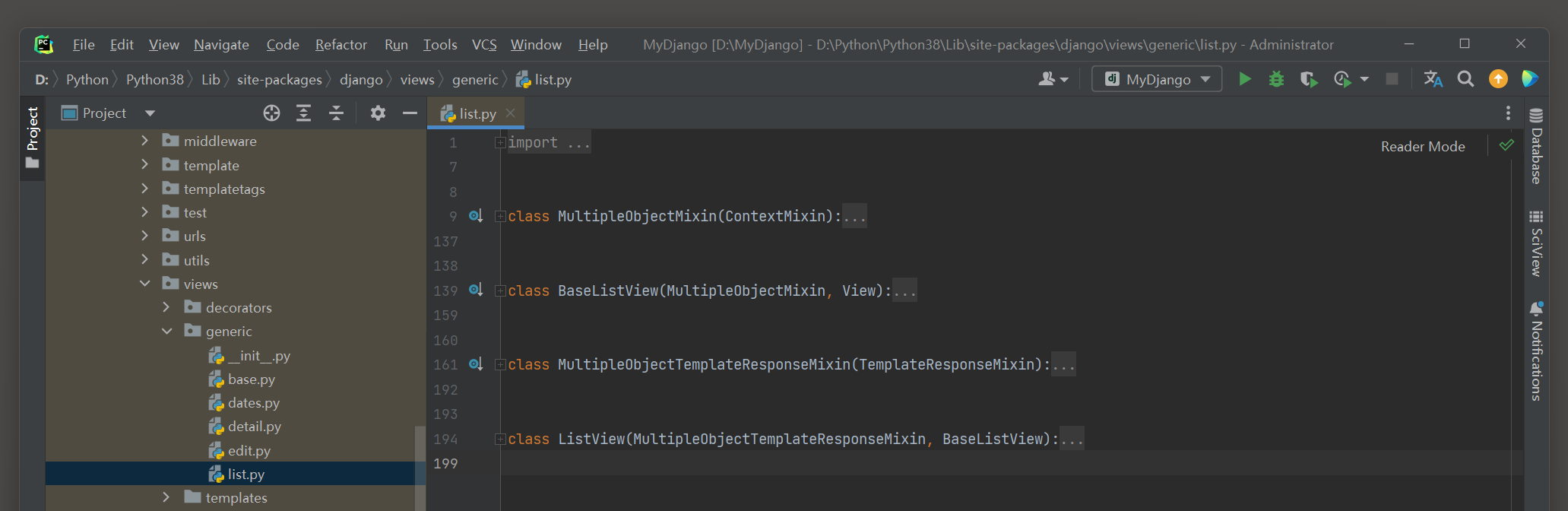
在PyCharm里打开视图类ListView的源码文件 , 分析视图类ListView的定义过程 , 如图 5 - 6 所示 .
图 5 - 6 视图类ListView的源码文件
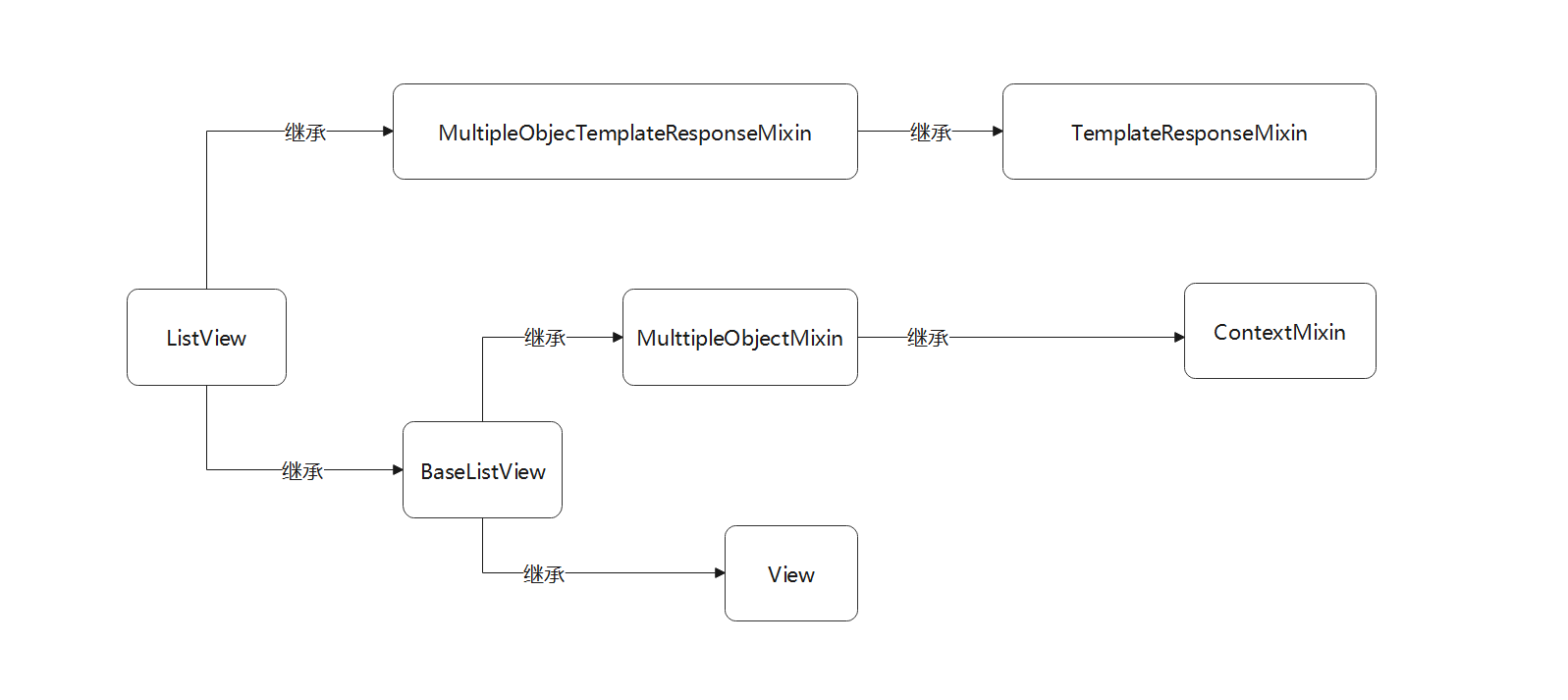
从视图类ListView的继承方式看到 , 它继承两个不同的父类 , 这些父类也继承其他的视图类 .
为了梳理类与类之间的继承关系 , 我们以流程图的形式表示 , 如图 5 - 7 所示 .
图 5 - 7 视图类ListView的继承过程
根据上述的继承关系可知 , 视图类ListView的底层类是由TemplateResponseMixin , ContextMixin和View组成的 ,
在这些底层类的基础上加入了模型的操作方法 , 从而得出视图类ListView .
分析视图类ListView的定义过程得知 , 它具有视图类TemplateView的所有属性和方法 , 因为两者的底层类是相同的 .
此外 , 视图类ListView新增了以下属性和方法 .
● allow_empty : 由MultipleObjectMixin定义 , 在模型查询数据不存在的情况下是否显示页面 ,
若为False并且数据不存在 , 则引发 404 异常 , 默认值为True .
● queryset : 由MultipleObjectMixin定义 , 代表模型的查询对象 , 这是对模型对象进行查询操作所生成的查询对象 .
● model : 由MultipleObjectMixin定义 , 代表模型 , 模型以类表示 , 一个模型代表一张数据表 .
● paginate_by : 由MultipleObjectMixin定义 , 属性值为整数 , 代表每一页所显示的数据量 .
● paginate_orphans : 由MultipleObjectMixin定义 , 属性值为整数 , 默认值为 0 ,
代表最后一页可以包含的 '溢出' 的数据量 , 防止最后一页的数据量过少 .
● context_object_name : 由MultipleObjectMixin定义 , 设置模板上下文 , 即为模板变量进行命名 .
● paginator_class : 由MultipleObjectMixin定义 , 设置分页的功能类 ,
默认情况下使用内置分页功能django . core . paginator . Paginator .
● page_kwarg : 由MultipleObjectMixin定义 , 属性值为字符串 , 默认值为page , 设置分页参数的名称 .
● ordering : 由MultipleObjectMixin定义 , 属性值为字符串或字符串列表 , 主要对属性queryset的查询结果进行排序 .
● get_queryset ( ) : 由MultipleObjectMixin定义 , 获取属性queryset的值 .
● get_ordering ( ) : 由MultipleObjectMixin定义 , 获取属性ordering的值 .
● paginate_queryset ( ) : 由MultipleObjectMixin定义 , 根据属性queryset的数据来进行分页处理 .
● get_paginate_by ( ) : 由MultipleObjectMixin定义 , 获取每一页所显示的数据量 .
● get_paginator ( ) : 由MultipleObjectMixin定义 , 返回当前页数所对应的数据信息 .
● get_paginate_orphans ( ) : 由MultipleObjectMixin定义 , 获取最后一页可以包含的 '溢出' 的数据量 .
● get_allow_empty ( ) : 由MultipleObjectMixin定义 , 获取属性allow_empty的属性值 .
● get_context_object_name ( ) : 由MultipleObjectMixin定义 , 设置模板上下文 ( 模板变量 ) 的名称 ,
若context_object_name未设置 , 则上下文名称将由模型名称的小写 + '_list' 表示 ,
比如模型PersonInfo , 其模板上下文的名称为personinfo_list .
● get_context_data ( ) : 由MultipleObjectMixin定义 , 获取模板上下文 ( 模板变量 ) 的数据内容 .
● template_name_suffix : 由MultipleObjectTemplateResponseMixin定义 , 设置模板后缀名 , 用于设置默认的模板文件 .
虽然视图类ListView定义了多个属性和方法 , 但实际开发中经常使用的属性和方法并不多 .
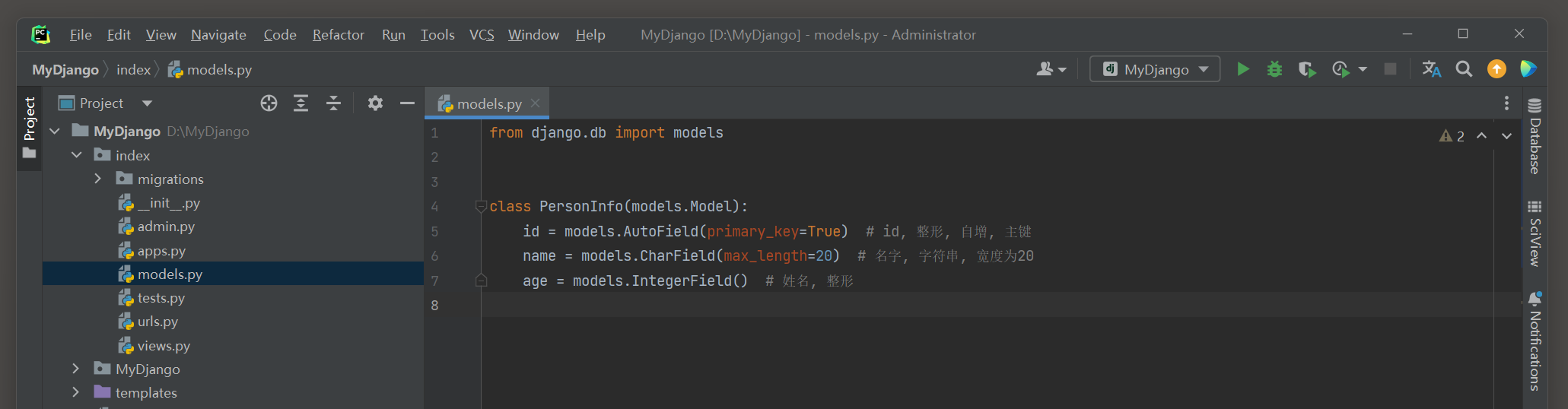
由于视图类ListView需要使用模型对象 , 因此在MyDjango项目里定义PersonInfo模型 , 在index的models . py中编写以下代码 :
from django. db import models
class PersonInfo ( models. Model) :
id = models. AutoField( primary_key= True )
name = models. CharField( max_length= 20 )
age = models. IntegerField( )
上述代码只是搭建PersonInfo类和数据表personinfo的映射关系 , 但在数据库中并没有生成相应的数据表 .
因此 , 下一步通过两者的映射关系在数据库里生成相应的数据表 .
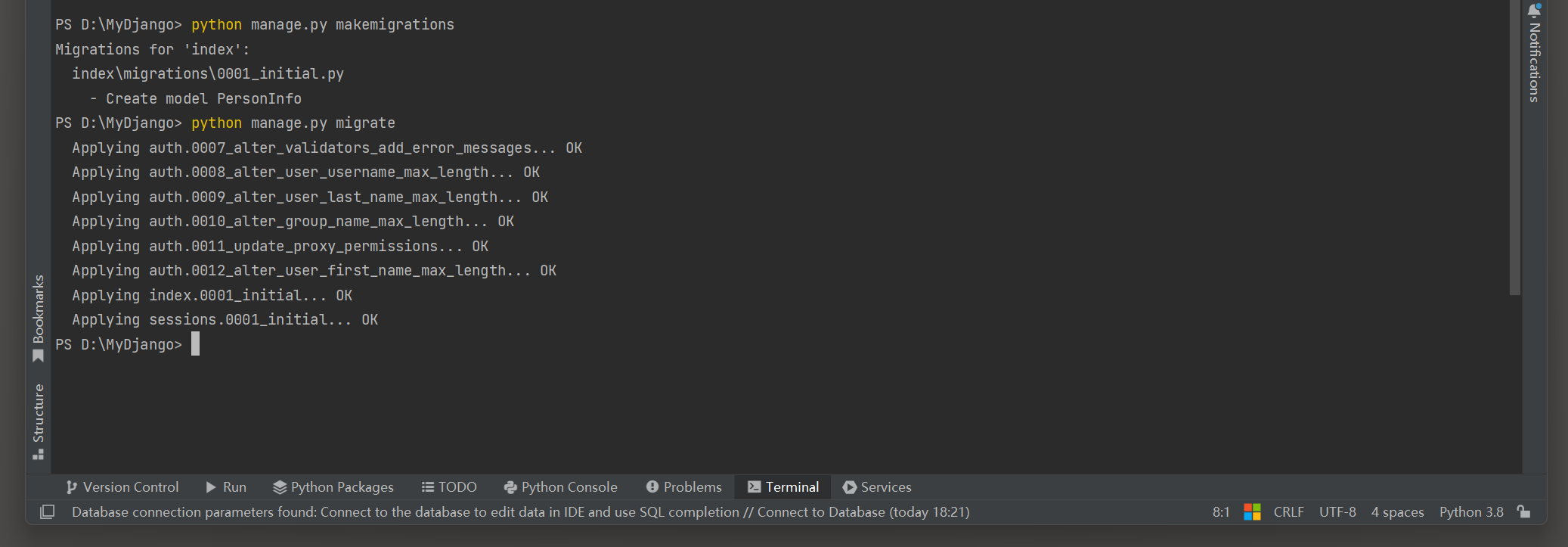
数据库以SQLite3为例 , 在PyCharm的Terminal里依次输入数据迁移指令 .
D: \MyDjango> python manage. py makemigrations
Migrations for 'index' :
index\migrations\0001_initial. py
- Create model personinfo
D: \MyDjango> python manage. py migrate
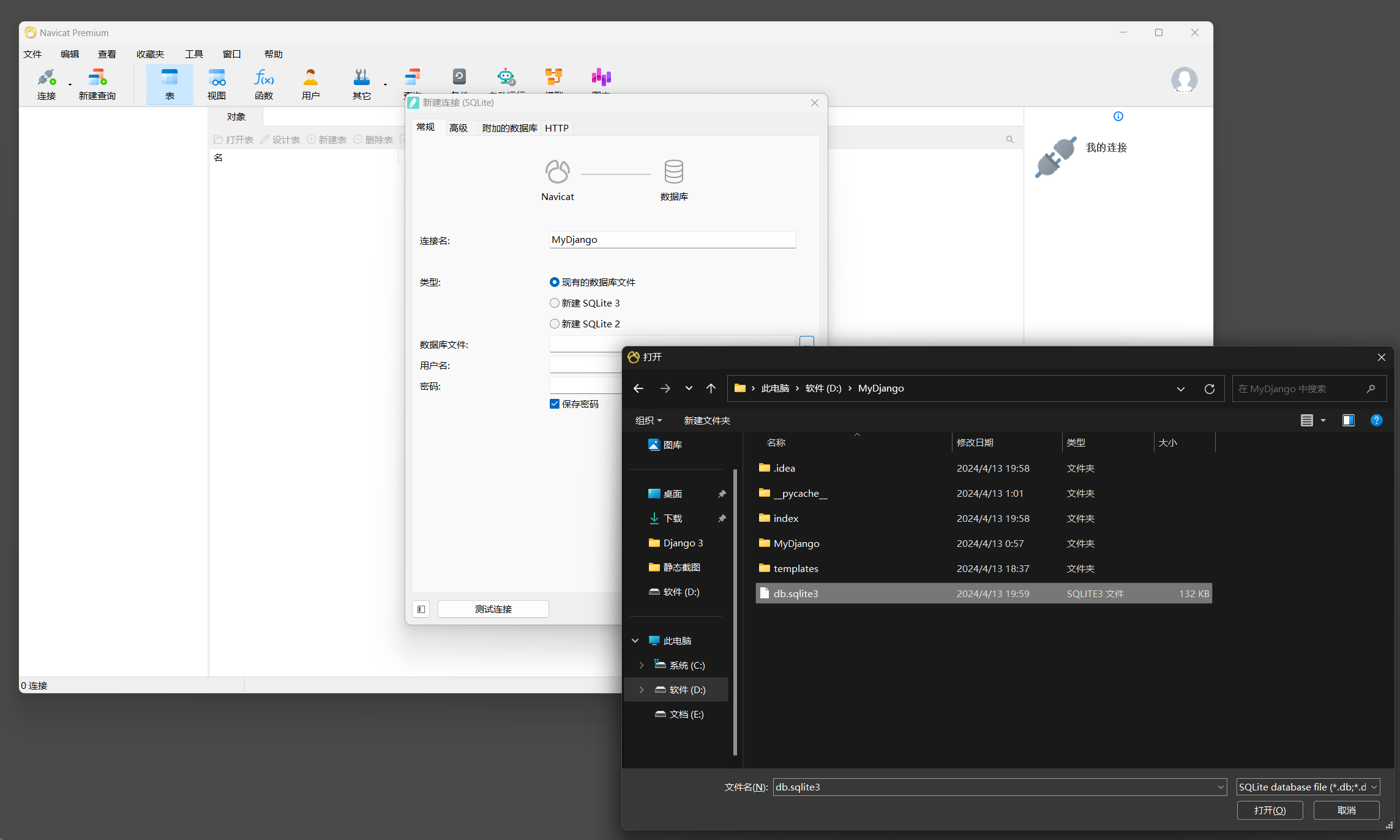
当指令执行完成后 , 使用Navicat Premium软件打开MyDjango的db . sqlite3文件 , 在此数据库中可以看到新创建的数据表 , 如图 5 - 8 所示 .
( 1. 点击连接 -- > 2. 选择SQLite -- > 3. 设置连接名称 -- > 4. 选择现有的数据库文件
-- > 5. 在数据库库文件中选择文件 ( 文件在项目下 ) -- > 6. 测试连接 -- > 7. 连接 )
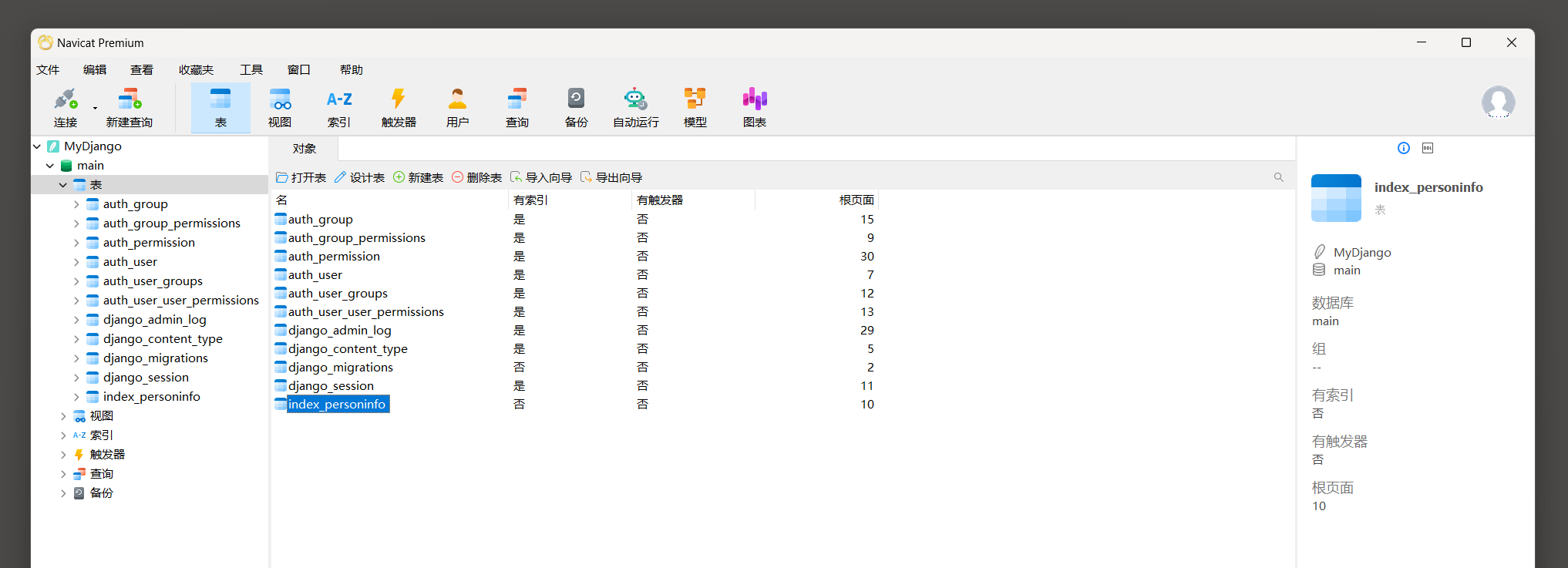
图 5 - 8 数据表信息
从图 5 - 8 中看到 , 当指令执行完成后 , Django会默认创建多个数据表 ,
其中数据表index_personinfo对应index的models . py中所定义的PersonInfo类 ,
其余的数据表都是Django内置的功能所生成的 , 主要用于Admin站点 , 用户认证和Session会话等功能 .
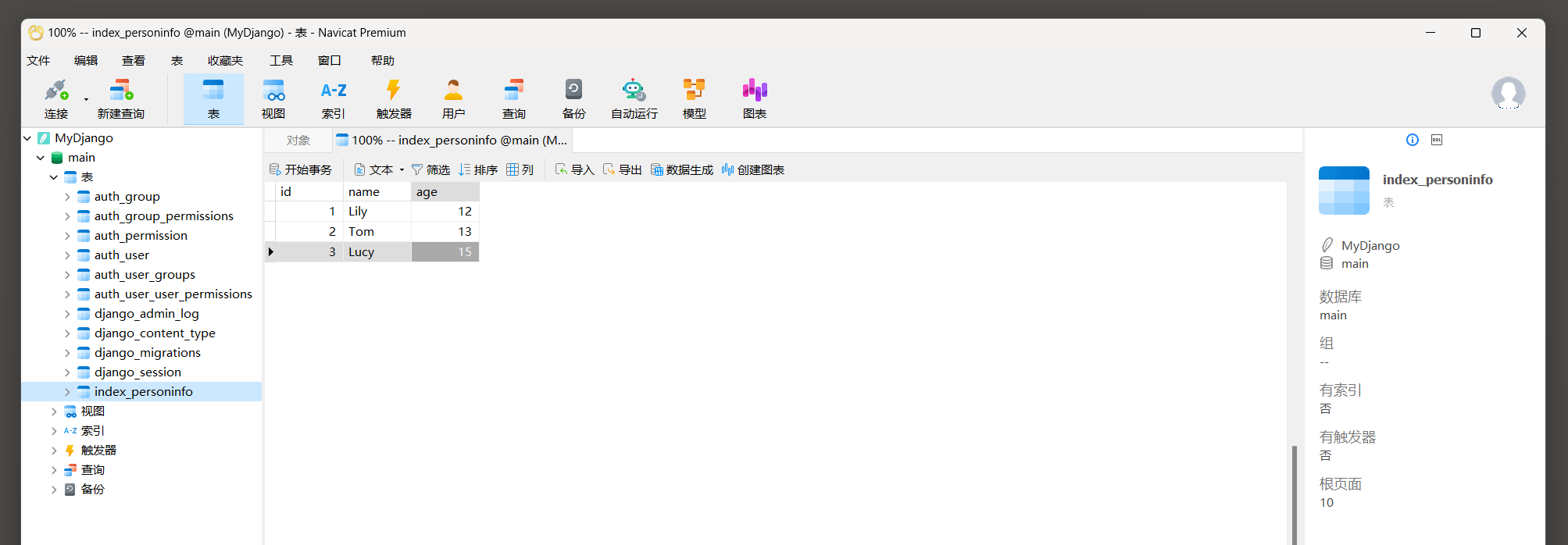
在数据表index_personinfo中添加如图 5 - 9 所示的数据 .
图 5 - 9 添加数据
完成上述操作后 , 下一步在MyDjango里使用视图类ListView ,
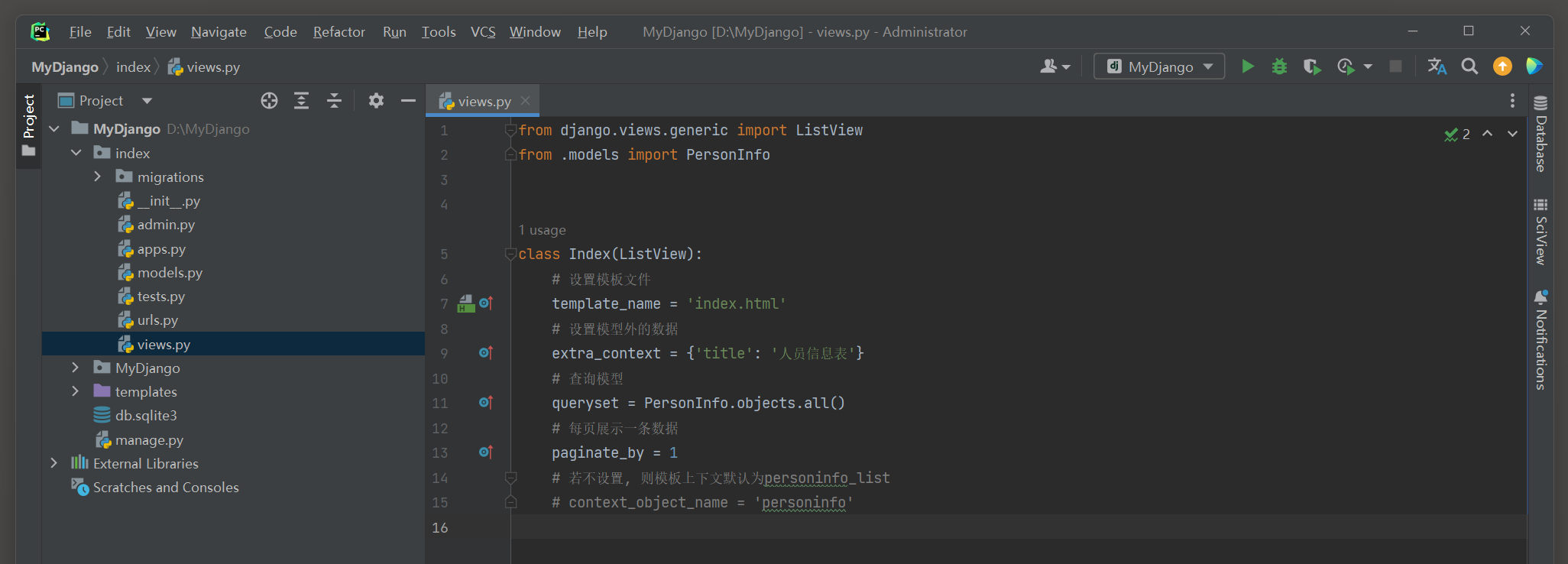
在index的views . py里定义视图类index , 并重新编写模板文件index . html的代码 :
from django. views. generic import ListView
from . models import PersonInfo
class Index ( ListView) :
template_name = 'index.html'
extra_context = { 'title' : '人员信息表' }
queryset = PersonInfo. objects. all ( )
paginate_by = 1
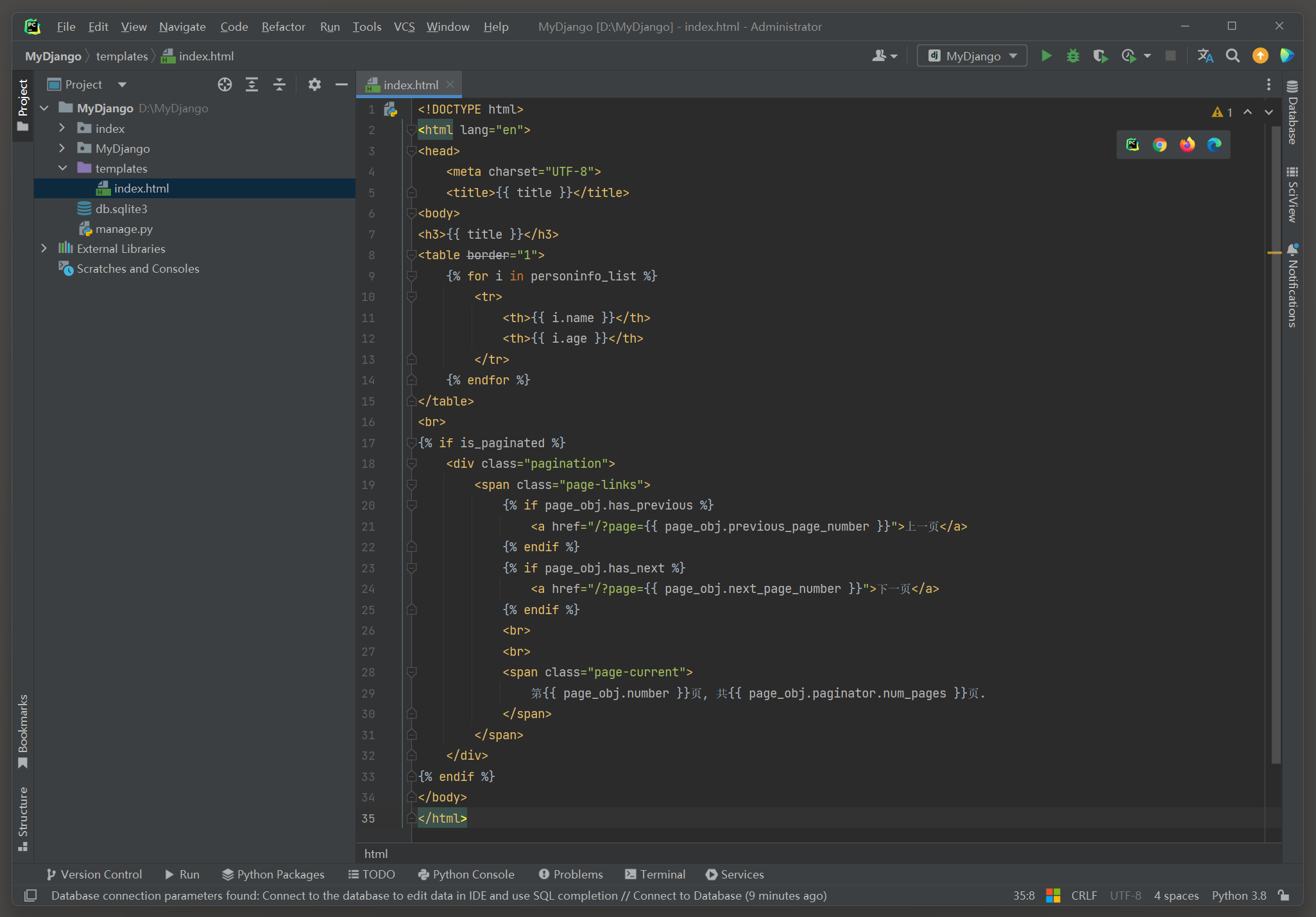
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> < body> < h3> </ h3> < tableborder = " 1" > < tr> < th> </ th> < th> </ th> </ tr> </ table> < br> < divclass = " pagination" > < spanclass = " page-links" > < ahref = " /?page={{ page_obj.previous_page_number }}" > </ a> < ahref = " /?page={{ page_obj.next_page_number }}" > </ a> < br> < br> < spanclass = " page-current" > </ span> </ span> </ div> </ body> </ html>
视图类index继承父类ListView , 并且仅设置 4 个属性就能完成模型数据的展示 .
视图类ListView虽然定义了多个属性和方法 , 但是大部分的属性和方法已有默认值和处理过程 , 这些就能满足日常开发需求 .
上述的视图类index仅支持HTTP的GET请求处理 , 因为父类ListView只定义了get ( ) 方法 ,
如果想让视图类index也能够处理POST请求 , 那么只需在该类下自定义post ( ) 方法即可 .
模板文件index . html按照功能可分为两部分 : 数据展示和分页功能 .
数据展示编写在HTML的table标签和title标签 , 模板上下文title ( { { title } } ) 是由视图类index属性extra_context传递的 ,
模板上下文personinfo_list来自视图类index的属性queryset所查询的数据 .
分页功能编写在div标签中 , 分页功能相关内容将会在后续章节详细讲述 .
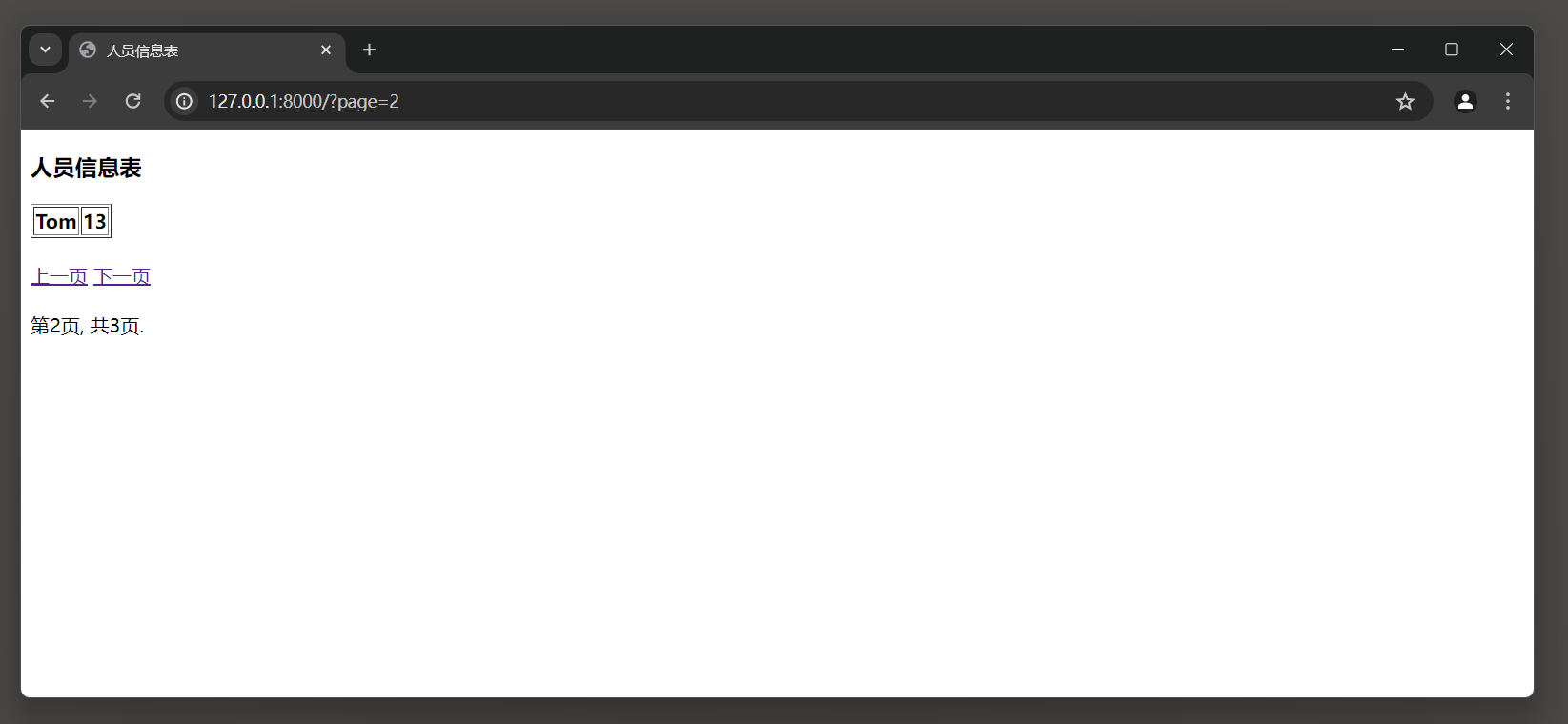
运行MyDjango项目 , 在浏览器上可以看到网页出现翻页功能 , 通过单击翻页链接可以查看数据表personinfo的数据信息 , 如图 5 - 10 所示 .
图 5 - 10 运行结果
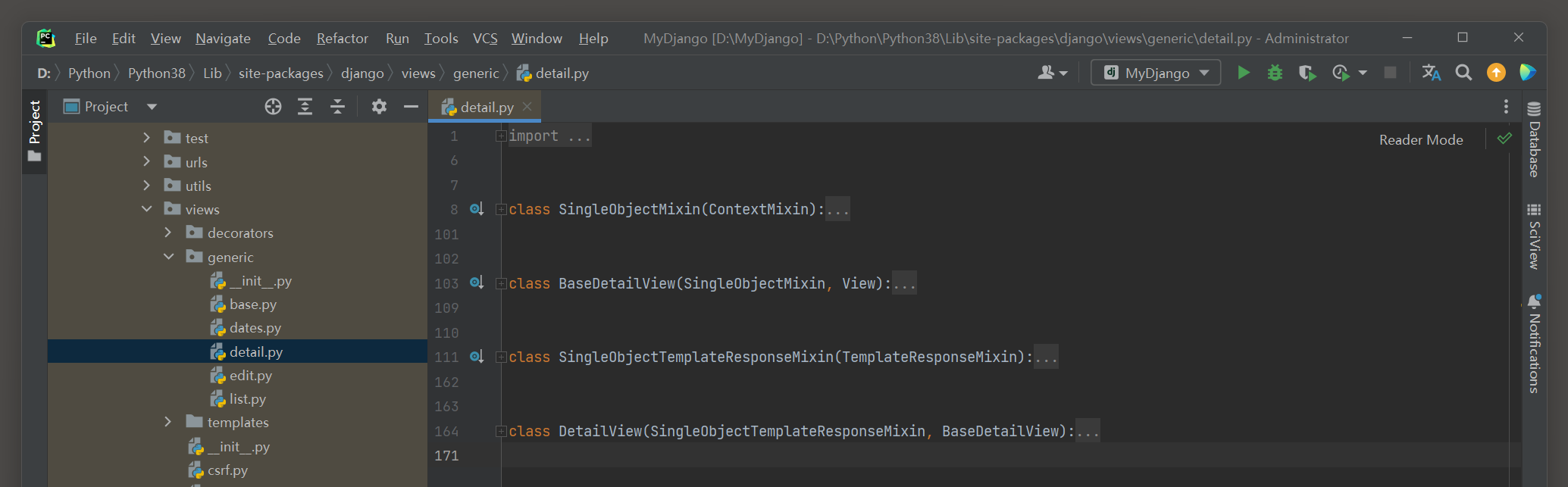
视图类DetailView是将数据库某一条数据详细显示在网页上 , 它与视图类ListView存在明显的差异 .
在PyCharm里打开视图类DetailView的源码文件 , 分析视图类DetailView的定义过程 , 如图 5 - 11 所示 .
图 5 - 11 视图类DetailView的源码文件
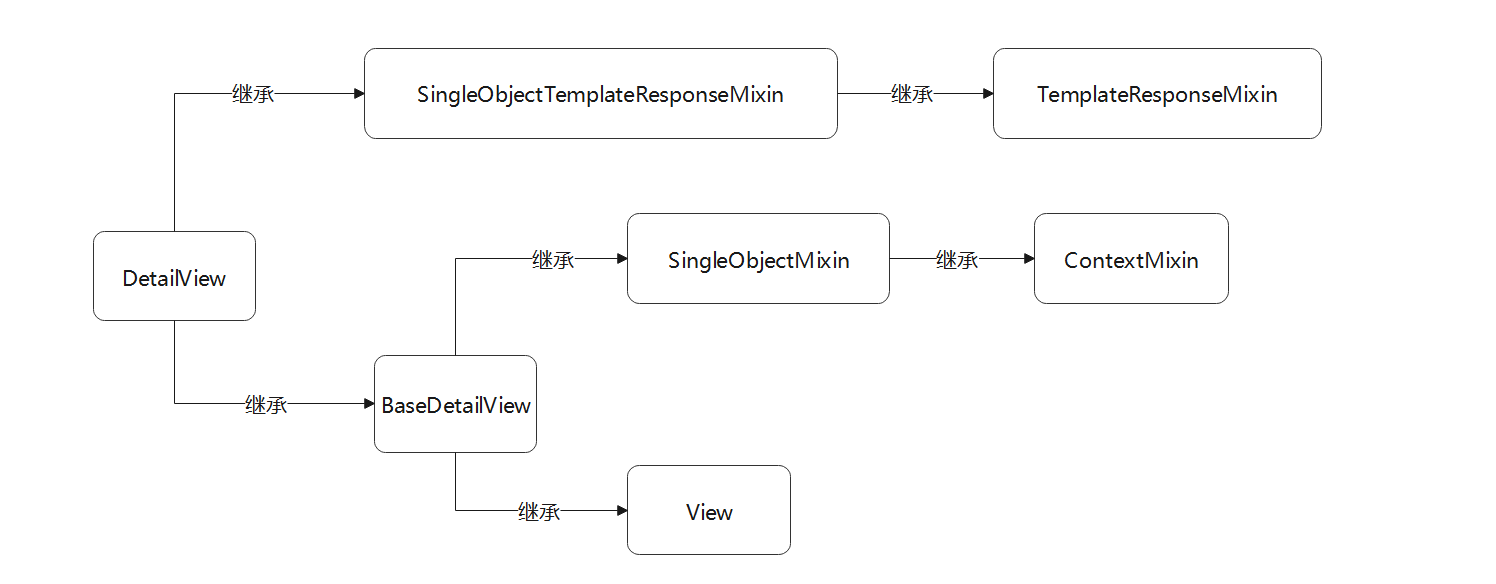
从视图类DetailView的继承方式看到 , 它继承两个不同的父类 , 这些父类也继承其他的视图类 .
为了梳理类与类之间的继承关系 , 我们以流程图的形式表示 , 如图 5 - 12 所示 .
图 5 - 12 视图类DetailView的继承过程
根据上述的继承关系可知 , 视图类DetailView的底层类由TemplateResponseMixin , ContextMixin和View组成 ,
它的设计模式与视图类ListView有一定的相似之处 .
分析视图类DetailView的定义过程得知 , 它不仅具有视图类TemplateView的所有属性和方法 , 还新增了以下属性和方法 .
● template_name_field : 由SingleObjectTemplateResponseMixin定义 , 用于确定模板的名称 .
● template_name_suffix : 由SingleObjectTemplateResponseMixin定义 ,
设置模板后缀名 , 默认后缀是_detail , 用于设置默认模板文件 .
● get ( ) : 由BaseDetailView定义 , 定义HTTP的GET请求的处理方法 .
● model : 由SingleObjectMixin定义 , 代表模型 , 模型以类表示 , 一个模型代表一张数据表 .
● queryset : 由SingleObjectMixin定义 , 这是对模型对象进行查询操作所生成的查询对象 .
● ontext_object_name : 由SingleObjectMixin定义 , 设置模板上下文 , 即为模板变量进行命名 .
● slug_field : 由SingleObjectMixin定义 , 设置模型的某个字段作为查询对象 , 默认值为slug .
● slug_url_kwarg : 由SingleObjectMixin定义 , 代表路由地址的某个变量 , 作为某个模型字段的查询范围 , 默认值为slug .
● pk_url_kwarg : 由SingleObjectMixin定义 , 代表路由地址的某个变量 , 作为模型主键的查询范围 , 默认值为pk .
● query_pk_and_slug : 由SingleObjectMixin定义 ,
若为True , 则使用属性pk_url_kwarg和slug_url_kwarg同时对模型进行查询 , 默认值为False .
● get_object ( ) : 由SingleObjectMixin定义 , 对模型进行单条数据查询操作 .
● get_queryset ( ) : 由SingleObjectMixin定义 , 获取属性queryset的值 .
● get_slug_field ( ) : 由SingleObjectMixin定义 , 根据属性slug_field查找与之对应的数据表字段 .
● get_context_object_name ( ) : 由SingleObjectMixin定义 , 设置模板上下文 ( 模板变量 ) 的名称 ,
若context_object_name未设置 , 则上下文名称将由模型名称的小写表示 , 比如模型PersonInfo , 其模板上下文的名称为personinfo .
● get_context_data ( ) : 由SingleObjectMixin定义 , 获取模板上下文 ( 模板变量 ) 的数据内容 .
从字面上理解新增的属性和方法有一定的难度 , 我们不妨以项目实例的形式来加以说明 .
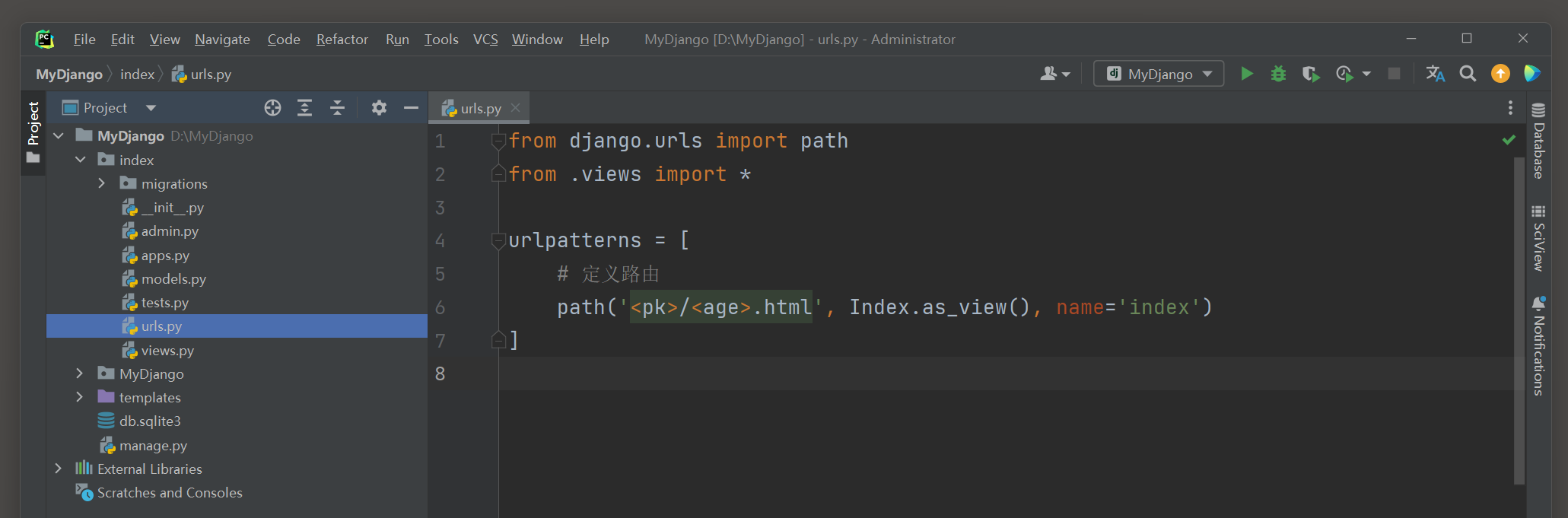
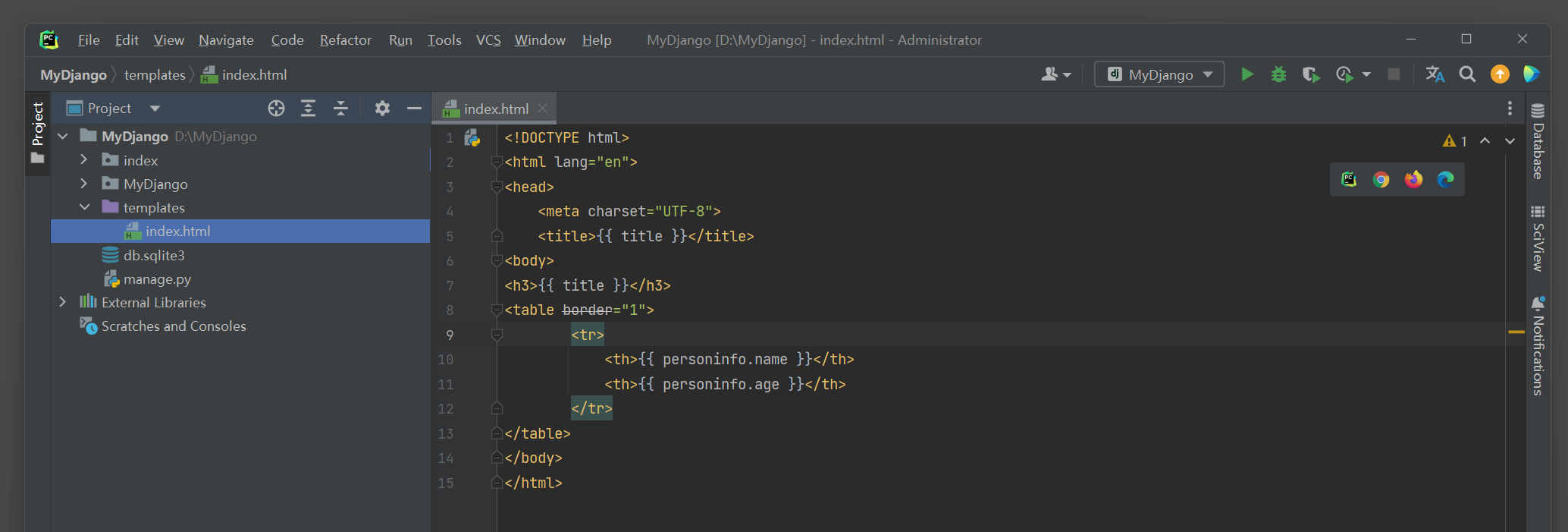
以MyDjango为例 , 沿用 5.1 .3 小节的模型PersonInfo ( index的models . py ) ,
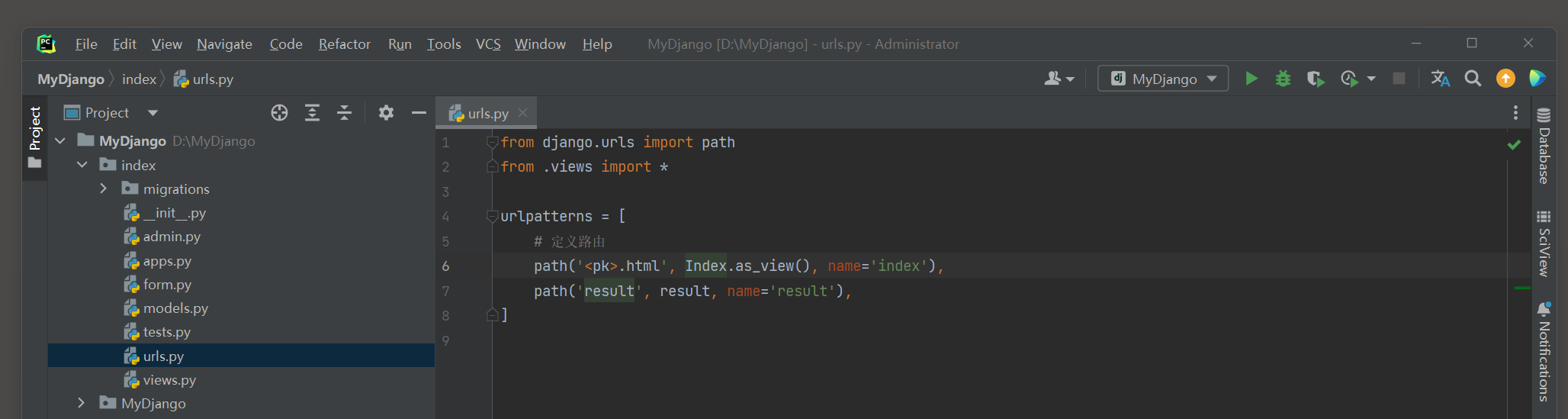
然后在index的urls . py , views . py和模板文件index . html中编写以下代码 :
from django. urls import path
from . views import *
urlpatterns = [
path( '<pk>/<age>.html' , Index. as_view( ) , name= 'index' )
]
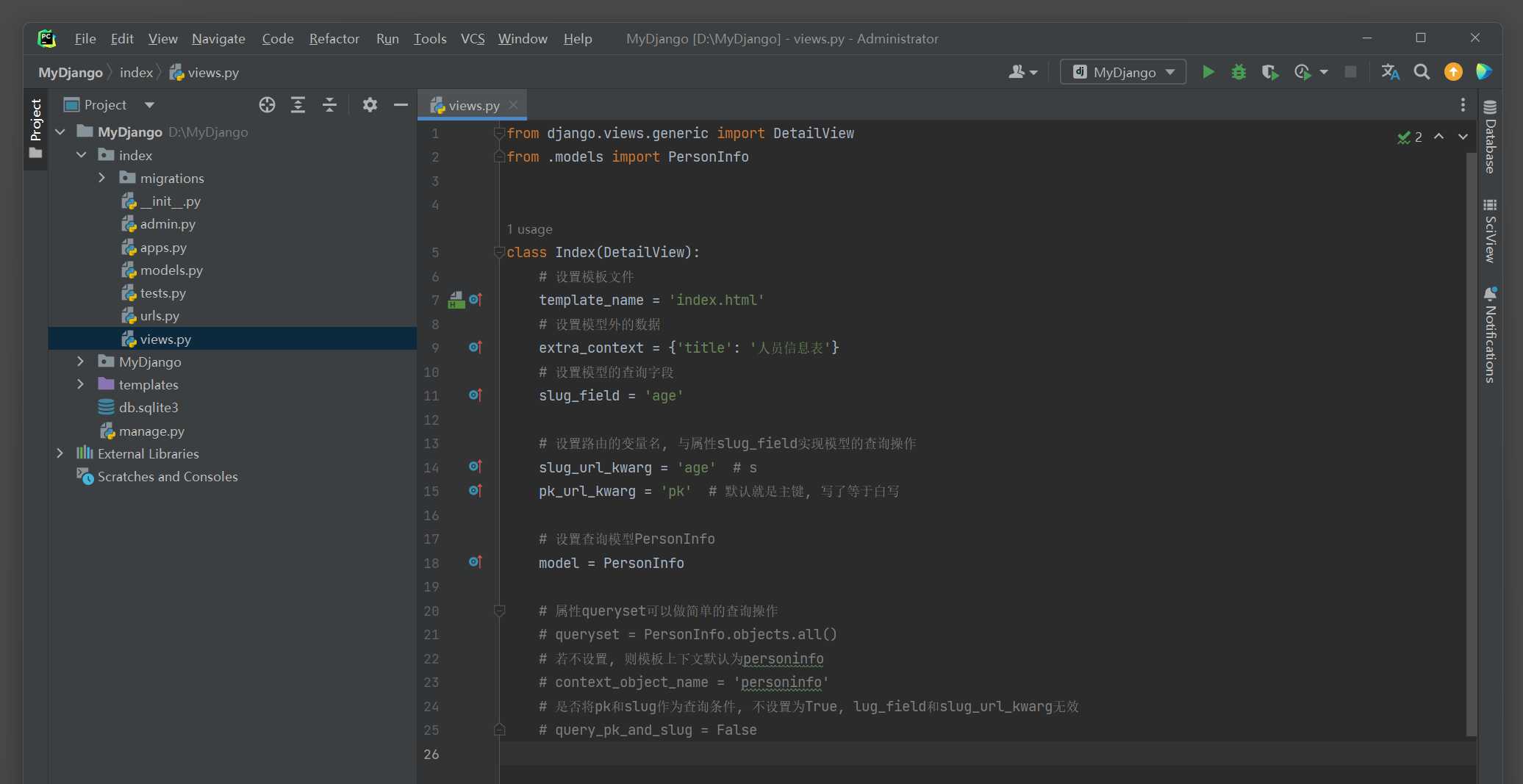
from django. views. generic import DetailView
from . models import PersonInfo
class Index ( DetailView) :
template_name = 'index.html'
extra_context = { 'title' : '人员信息表' }
slug_field = 'age'
slug_url_kwarg = 'age'
pk_url_kwarg = 'pk'
model = PersonInfo
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> < body> < h3> </ h3> < tableborder = " 1" > < tr> < th> </ th> < th> </ th> </ tr> </ table> </ body> </ html>
路由index设有两个路由变量pk和age , 这两个变量为模型PersonInfo的字段id和age提供查询范围 .
视图类index的属性model以模型PersonInfo作为查询对象 ;
属性pk_url_kwarg和slug_url_kwarg用于获取指定的路由变量 ,
比如属性pk_url_kwarg , 其值为pk , 等同于路由变量pk的变量名 ,
视图类index会根据该值来获取路由变量pk的值 , 而且该属性以模型的主键作为查询条件 , 假如路由变量pk的值为 10 ,
视图类index先从属性pk_url_kwarg获取路由变量pk的值 , 再从模型查询主键id等于 10 的数据 .
再举例说明 , 属性slug_url_kwarg的值为age , 它指向路由变量age ,
视图类index会根据属性slug_url_kwarg的值来获取路由变量age的值 ,
再从属性slug_field来确定查询的字段 , 假设属性slug_field的值为age , 路由变量age的值为 15 ,
视图类index将模型字段age等于 15 的数据查询出来 .
假设属性slug_field的值改为name , 属性slug_url_kwarg的值改为name , 路由变量name的值为Tom ,
那么视图类index将模型字段name等于Tom的数据查询出来 .
如果没有设置属性context_object_name , 查询出来的结果就以模型名称的小写表示 , 主要用于模板上下文 .
比如模型PersonInfo , 查询出来的结果将命名为personinfo , 并且传到模板文件index . html作为模板上下文 .
属性query_pk_and_slug用于设置查询字段的优先级 , 属性pk_url_kwarg用于查询模型的主键 , 属性slug_url_kwarg用于查询模型其他字段 .
如果query_pk_and_slug为False , 那么优先查询模型的主键 , 若为True , 则将主键和slug_field所设置的字段一并查询 .
综上所述 , 视图类DetailView的属性pk_url_kwarg和slug_url_kwarg用于确定模型的查询条件 ;
属性slug_field用于确定模型的查询字段 ; 属性query_pk_and_slug用于确定模型主键和其他字段的组合查询 .
启动项目 , 输入地址 : http : / / 127.0 .0 .1 : 8000 / 1 / 12. html , 通过主键获取数据 .
数据操作视图是对模型进行操作 , 如增 , 删 , 改 , 从而实现Django与数据库的数据交互 .
数据操作视图有 4 个视图类 , 分别是FormView , CreateView , UpdateView和DeleteView , 说明如下 :
● FormView视图类使用内置的表单功能 , 通过表单实现数据验证 , 响应输出等功能 , 用于显示表单数据 .
● CreateView实现模型的数据新增功能 , 通过内置的表单功能实现数据新增 .
● UpdateView实现模型的数据修改功能 , 通过内置的表单功能实现数据修改 .
● DeleteView实现模型的数据删除功能 , 通过内置的表单功能实现数据删除 .
视图类FormView是表单在视图里的一种使用方式 , 表单是搜集用户数据信息的各种表单元素的集合 ,
作用是实现网页上的数据交互 , 用户在网站输入数据信息 , 然后提交到网站服务器端进行处理 , 如数据录入和用户登录 , 注册等 .
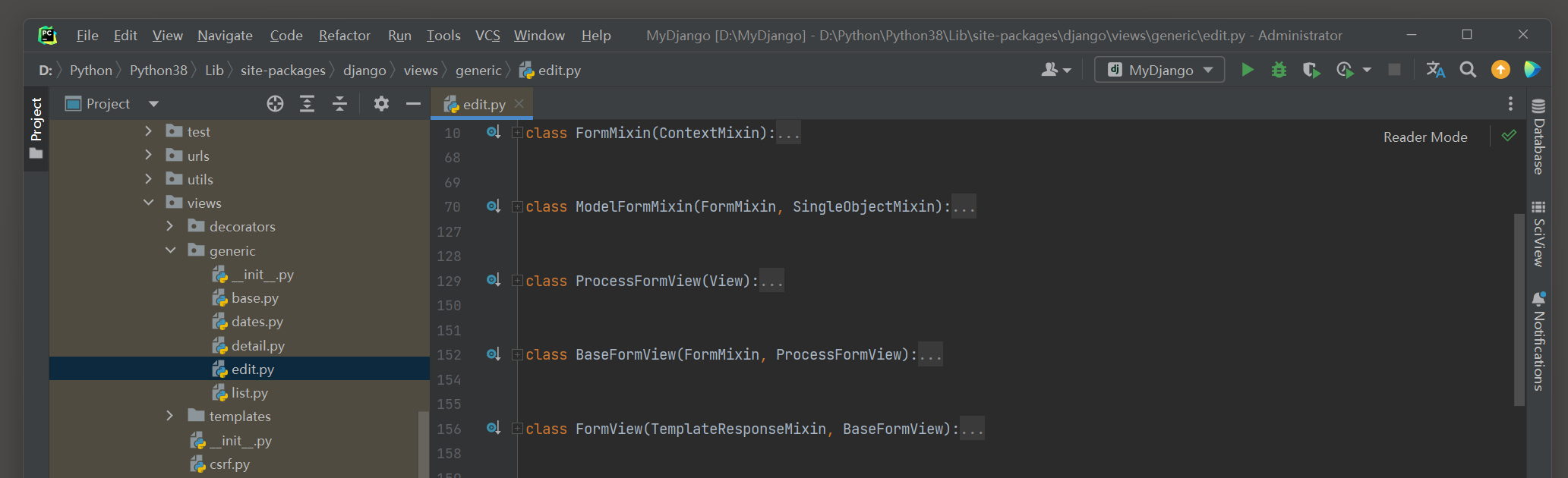
在PyCharm里打开视图类FormView的源码文件 , 分析视图类FormView的定义过程 , 如图 5 - 13 所示 .
图 5 - 13 视图类FormView的源码文件
从视图类FormView的继承方式可以看到 , 它也是继承两个不同的父类 , 而父类继承其他的视图类 .
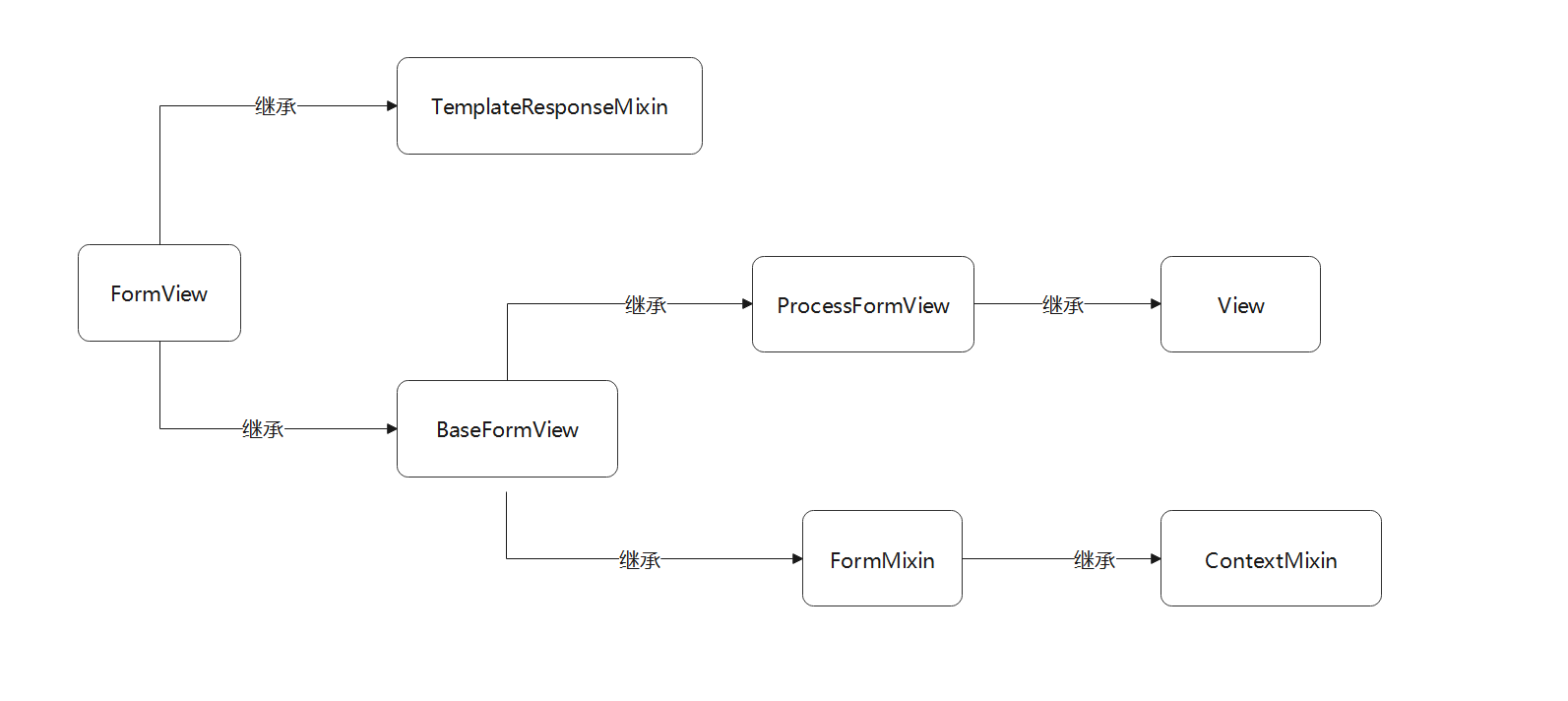
为了梳理类与类之间的继承关系 , 我们以流程图的形式表示 , 如图 5 - 14 所示 .
图 5 - 14 视图类FormView的继承过程
根据上述的继承关系可知 , 视图类FormView的底层类是由TemplateResponseMixin , ContextMixin和View组成的 ,
设计模式与其他视图类十分相似 .
分析视图类FormView的定义过程得知 , 它不仅具有视图类TemplateView的所有属性和方法 , 还新增了以下属性和方法 .
● initial : 由FormMixin定义 , 设置表单初始化的数据 .
● form_class : 由FormMixin定义 , 设置表单类 .
● success_url : 由FormMixin定义 , 设置重定向的路由地址 .
● prefix : 由FormMixin定义 , 设置表单前缀 ( 即表单在模板的上下文 ) , 可在模板里生成表格数据 .
● get_initial ( ) : 由FormMixin定义 , 获取表单初始化的数据 .
● get_prefix ( ) : 由FormMixin定义 , 获取表单的前缀 .
● get_form_class ( ) : 由FormMixin定义 , 获取表单类 .
● get_form ( ) : 由FormMixin定义 , 调用get_form_kwargs ( ) 完成表单类的实例化 .
● get_form_kwargs ( ) : 由FormMixin定义 , 执行表单类实例化的过程 .
● get_success_url ( ) : 由FormMixin定义 , 获取重定向的路由地址 .
● form_valid ( ) : 由FormMixin定义 , 表单有效将会重定向到指定的路由地址 .
● form_invalid ( ) : 由FormMixin定义 , 表单无效将会返回空白表单 .
● get_context_data ( ) : 由FormMixin定义 , 获取模板上下文 ( 模板变量 ) 的数据内容 .
● get ( ) : 由ProcessFormView定义 , 定义HTTP的GET请求的处理方法 .
● post ( ) : 由ProcessFormView定义 , 定义HTTP的POST请求的处理方法 .
以项目实例的形式来加以说明新增的属性和方法 .
在MyDjango项目里 , 沿用 5.1 .3 小节所定义的模型PersonInfo ( index的models . py ) ,
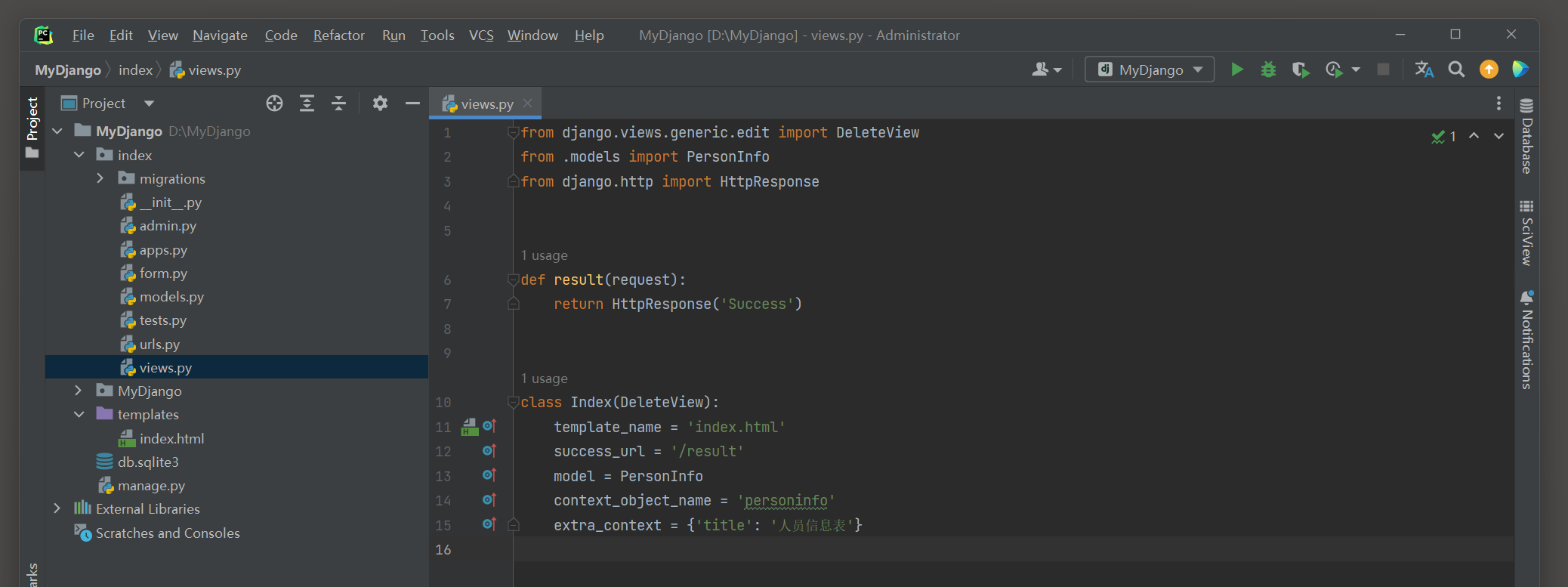
并在index文件夹里创建form . py文件 , 最后在index的form . py , urls . py , views . py和模板文件index . html中分别编写以下代码 :
from django import forms
from . models import PersonInfo
class PersonInfoForm ( forms. ModelForm) :
class Meta :
model = PersonInfo
fields = '__all__'
from django. urls import path
from . views import *
urlpatterns = [
path( '' , Index. as_view( ) , name= 'index' ) ,
path( 'result' , result, name= 'result' )
]
from django. views. generic. edit import FormView
from . form import PersonInfoForm
from django. http import HttpResponse
def result ( request) :
return HttpResponse( 'Success' )
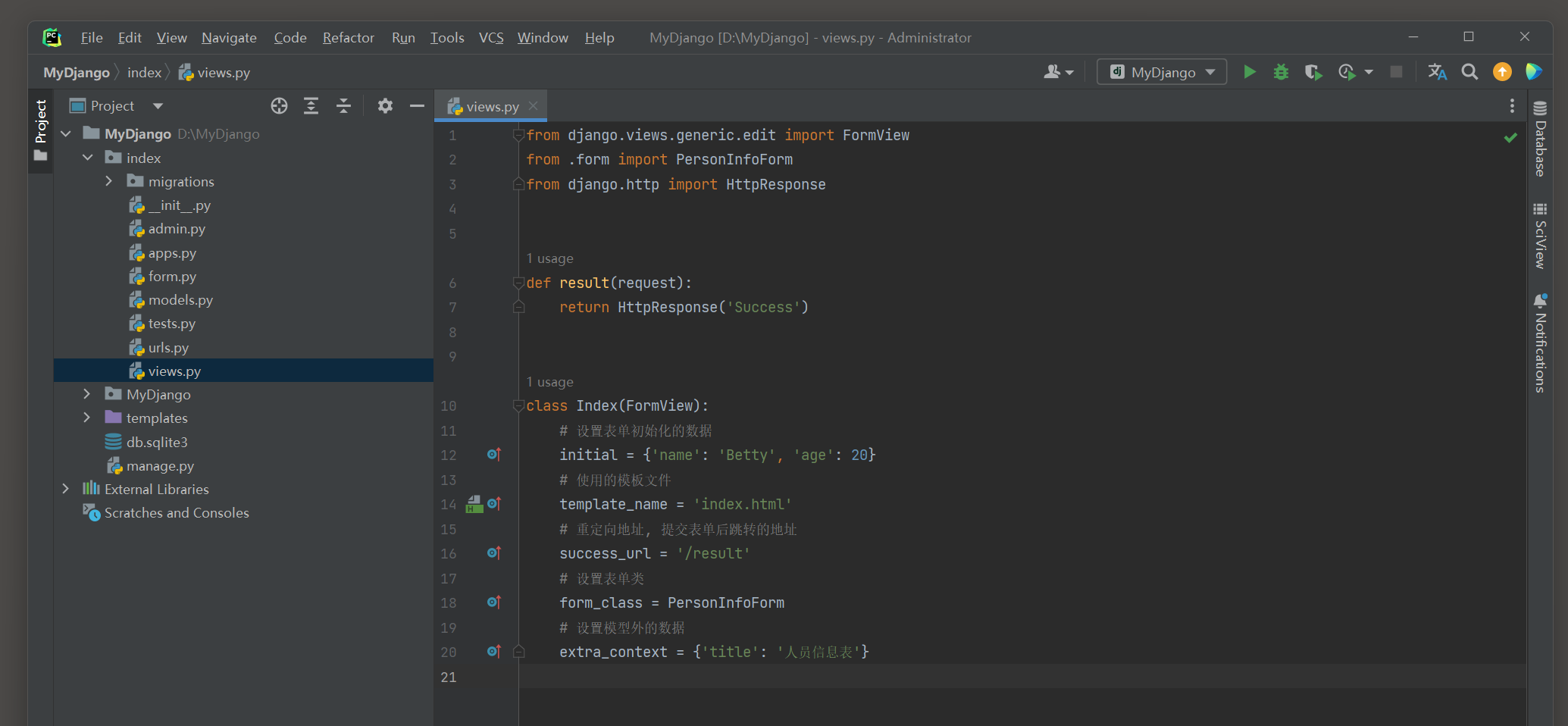
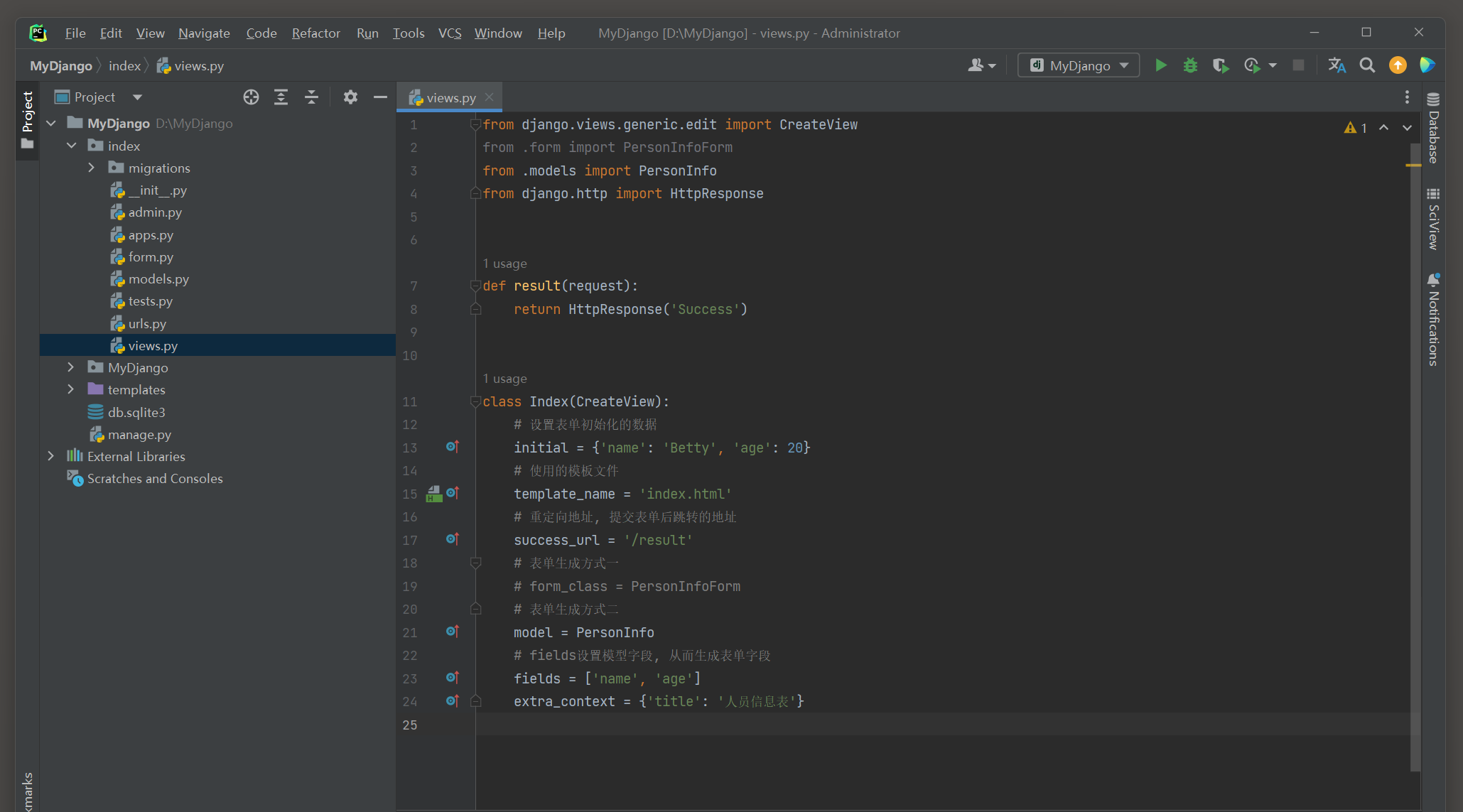
class Index ( FormView) :
initial = { 'name' : 'Betty' , 'age' : 20 }
template_name = 'index.html'
success_url = '/result'
form_class = PersonInfoForm
extra_context = { 'title' : '人员信息表' }
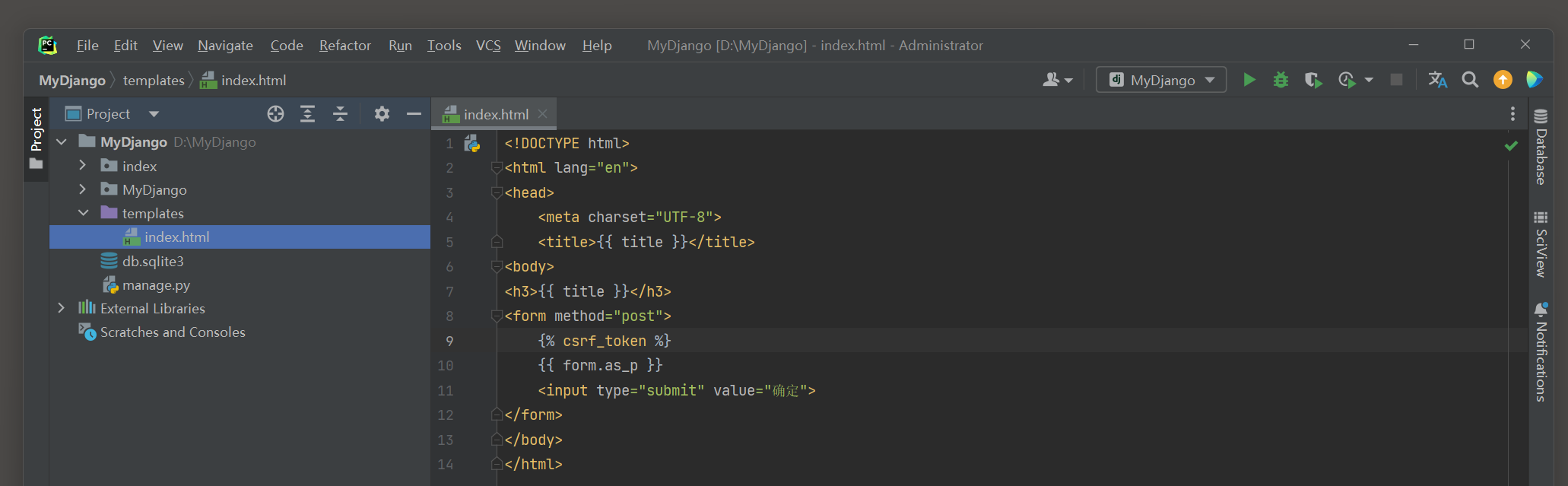
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> < body> < h3> </ h3> < formmethod = " post" > < inputtype = " submit" value = " 确定" > </ form> </ body> </ html>
上述代码是视图类FormView的简单应用 , 它涉及模型和表单的使用 , 说明如下 :
● index的form . py里定义了表单类PersonInfoForm , 该表单是根据模型PersonInfo定义的模型表单 , 表单的字段来自模型的字段 .
有关表单的知识点将会在第 8 章详细讲述 .
● 路由index的请求处理由视图类FormView完成 , 而路由result为视图类index的属性success_url提供路由地址 .
● 视图类index仅设置了 5 个属性 , 属性extra_context的值对应模板上下文title ;
属性form_class所设置的表单在实例化之后可在模板里使用上下文form . as_p生成表格 ,
模板上下文form的命名是固定的 , 它来自类FormMixin的get_context_data ( ) .
● 在网页上单击 '确定' 按钮 , 视图类index就会触发父类FormView所定义的post ( ) 方法 ,
然后调用表单内置的is_valid ( ) 方法对表单数据进行验证 .
如果验证有效 , 就调用form_valid ( ) 执行重定向处理 , 重定向的路由地址由属性success_url提供 ;
如果验证无效 , 就调用form_invalid ( ) , 在当前页面返回空白的表单 .
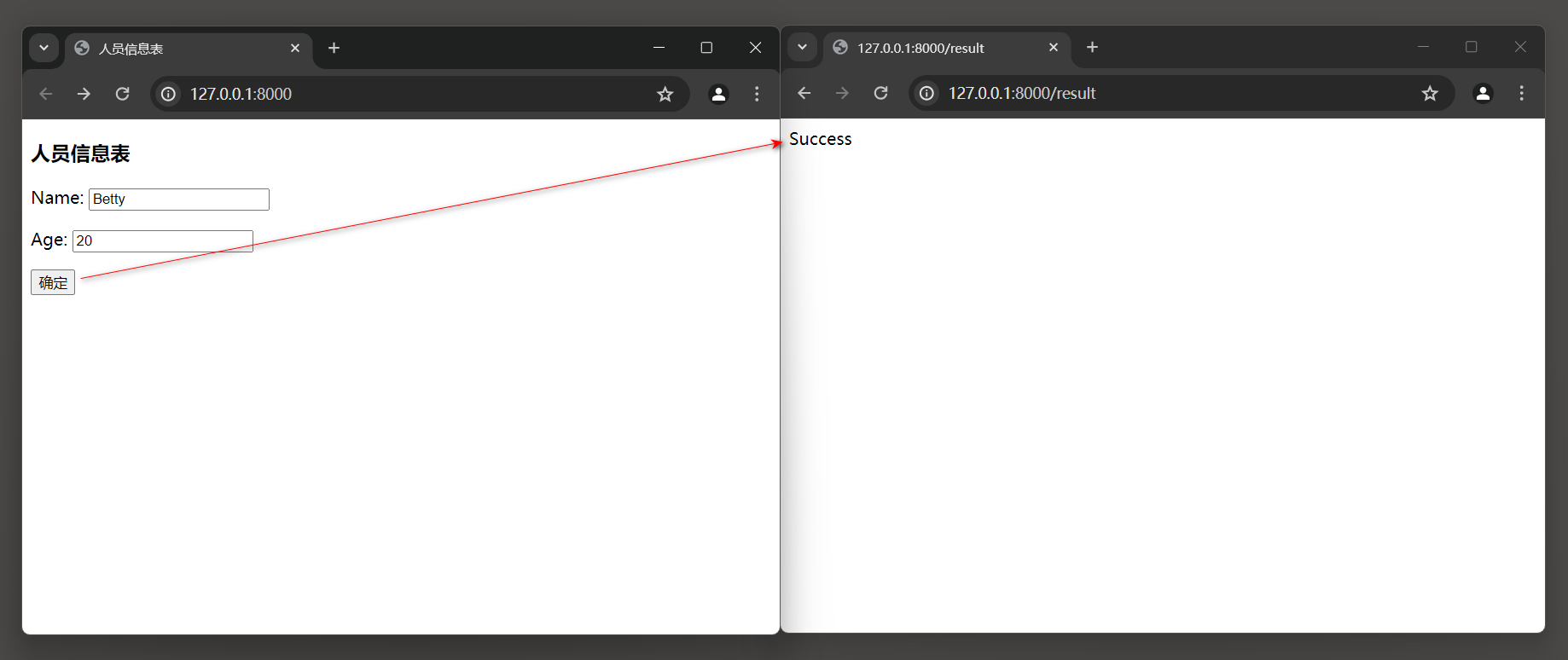
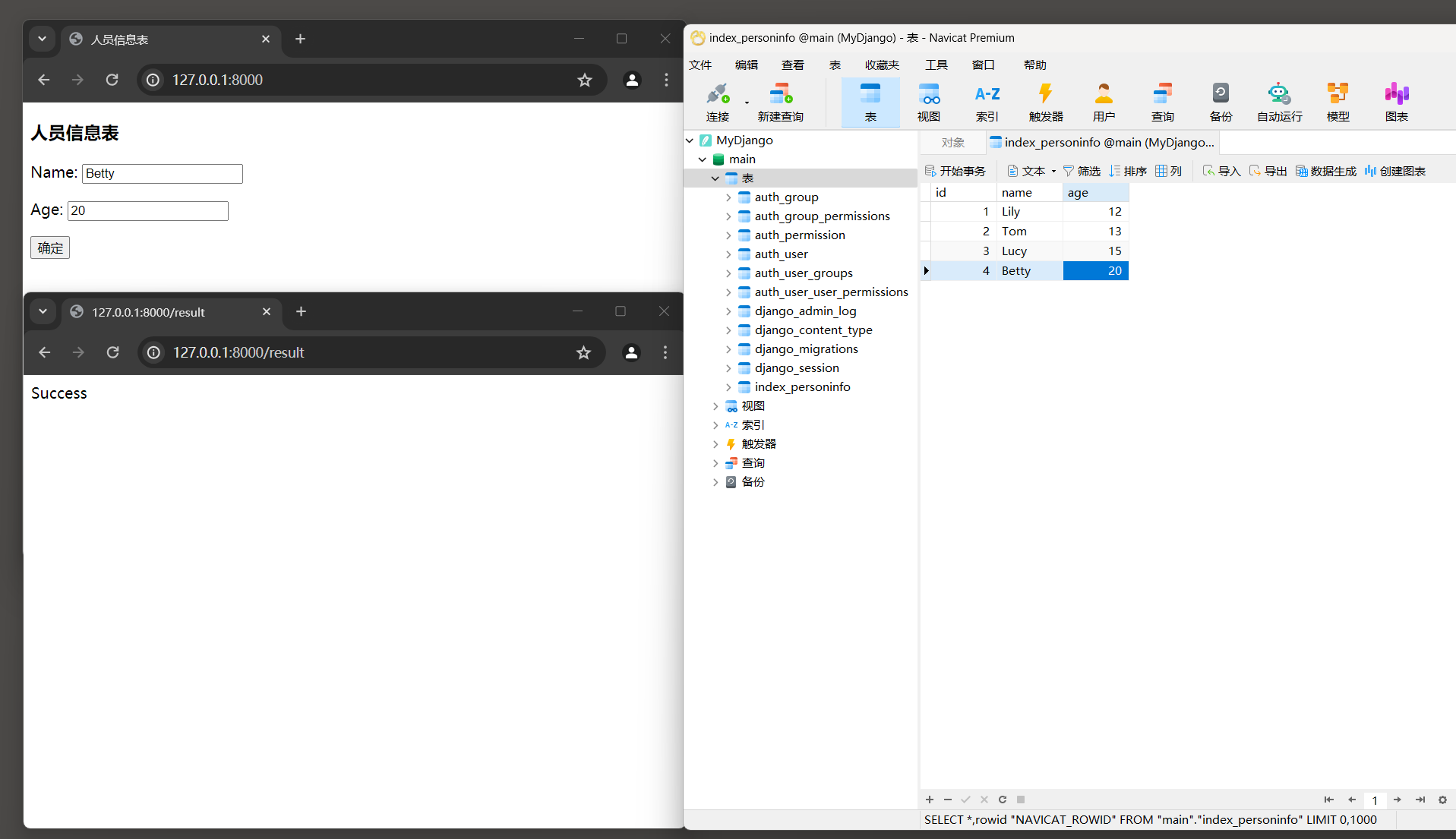
运行MyDjango项目 , 在浏览器上访问 127.0 .0 .1 : 8000 , 发现表单上设有数据 , 这是由视图类index的属性initial设置的 .
单击 '确定' 按钮 , 浏览器就会自动跳转到路由result , 说明表单验证成功 , 如图 5 - 15 所示 .
图 5 - 15 运行结果
视图类CreateView是对模型新增数据的视图类 , 它是在表单视图类FormView的基础上加以封装的 .
简单来说 , 就是在视图类FormView的基础上加入数据新增的功能 .
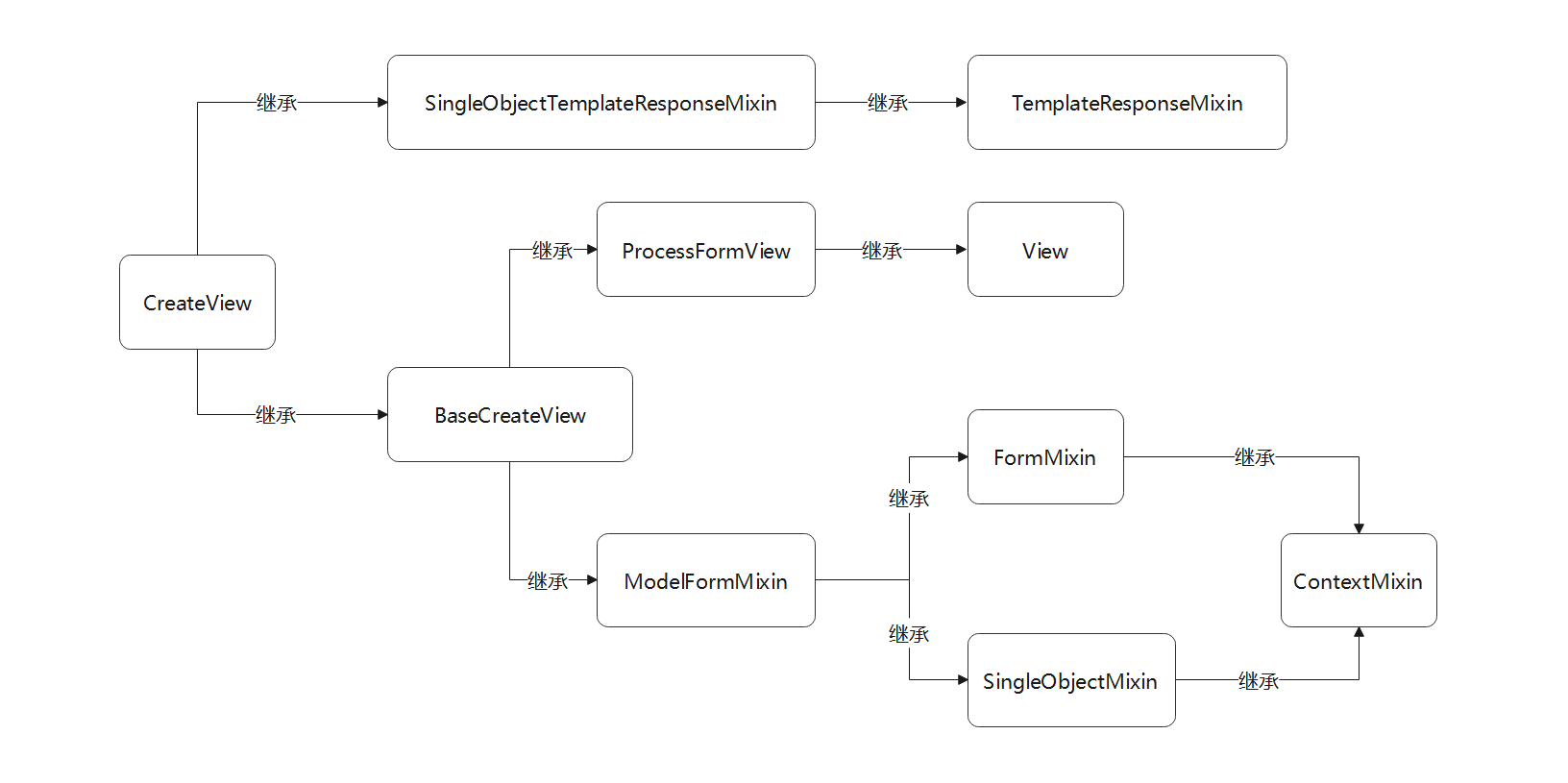
视图类CreateView与FormView是在同一个源码文件里定义的 , 在源码文件里分析视图类CreateView的定义过程 ,
以流程图的形式表述类的继承关系 , 如图 5 - 16 所示 .
图 5 - 16 视图类CreateView的继承过程
从上述的继承关系可知 , 视图类CreateView的底层类是由TemplateResponseMixin , ContextMixin和View组成的 , 整个设计共继承 8 个类 .
分析视图类CreateView的定义过程得知 , 它不仅具有视图类TemplateView , SingleObjectMixin和FormView的所有属性和方法 ,
还新增或重写了以下属性和方法 :
● fields : 由ModelFormMixin定义 , 设置模型字段 ,
以列表表示 , 每个字段代表一个列表元素 , 可生成表单的数据列表 , 为用户提供数据输入 .
● get_form_class ( ) : 由ModelFormMixin定义 , 重写FormMixin的方法 ,
根据属性fields和form_class的组合情况进行判断 , 从而选择表单的生成方式 .
● get_form_kwargs ( ) : 由ModelFormMixin定义 , 重写FormMixin的方法 .
● get_success_url ( ) : 由ModelFormMixin定义 , 重写FormMixin的方法 ,
判断属性success_url是否为空 , 若为空 , 则从模型的内置方法get_absolute_url ( ) 获取重定向的路由地址 .
● form_valid ( ) : 由ModelFormMixin定义 , 重写FormMixin的表单验证方法 , 新增表单数据保存到数据库的功能 .
● template_name_suffix : 由CreateView定义 , 设置模板的后缀名 , 用于设置默认的模板文件 .
视图类CreateView虽然具备TemplateView , SingleObjectMixin和FormView的所有属性和方法 ,
但经过重写某些方法后 , 导致其运行过程已发生变化 , 其中最大的特点在于get_form_class ( ) 方法 ,
它是通过判断属性form_class ( 来自FormMixin类 ) ,
fields ( 来自ModelFormMixin类 ) 和model ( 来自SingleObjectMixin类 ) , 从而实现数据新增操作 .
其判断方法如下 :
● 若fields和form_class都不等于None , 则抛出异常 , 提示不允许同时设置fields和form_class .
● 若form_class不等于None且fields等于None , 则返回form_class .
● 若form_class等于None , 则从属性model , object和get_queryset ( ) 获取模型对象 .
同时判断属性fields是否为None , 若为None , 则抛出异常 ;
若不为None , 则根据属性fields生成表单对象 , 由表单内置的modelform_factory ( ) 方法实现 .
综上所述 , 视图类CreateView有两种表单生成方式 .
第一种是设置属性form_class , 通过属性form_class指定表单对象 ,
这种方式需要开发者自定义表单对象 , 假如自定义的表单和模型的字段不相符 , 在运行过程中很容易出现异常情况 .
第二种是设置属性model和fields , 由模型对象和模型字段来生成相应的表单对象 ,
生成的表单字段与模型的字段要求相符 , 可以减少异常情况 , 并且无须开发者自定义表单对象 .
沿用 5.2 .1 小节的MyDjango项目 , index的form . py , urls . py和模板文件index . html中的代码无须修改 ,
只需修改index的views . py , 代码如下 :
from django. views. generic. edit import CreateView
from . form import PersonInfoForm
from . models import PersonInfo
from django. http import HttpResponse
def result ( request) :
return HttpResponse( 'Success' )
class Index ( CreateView) :
initial = { 'name' : 'Betty' , 'age' : 20 }
template_name = 'index.html'
success_url = '/result'
model = PersonInfo
fields = [ 'name' , 'age' ]
extra_context = { 'title' : '人员信息表' }
视图类index只需设置某些类属性即可完成模型数据的新增功能 , 整个数据新增过程都由视图类CreateView完成 .
视图类index还列举了两种表单生成方式 , 默认使用属性model和fields生成表单 ,
读者可将属性form_class的注释清除 , 并对属性model和fields进行注释处理 , 即可使用第一种表单生成方式 .
运行MyDjango项目 , 在浏览器上访问 : 127.0 .0 .1 : 8000 , 发现表单上设有数据 , 这是由视图类index的属性initial设置的 .
单击 '确定' 按钮 , 浏览器就会自动跳转到路由result , 说明表单验证成功 .
在Navicat Premium里打开MyDjango的db . sqlite3数据库文件 , 查看数据表index_personinfo的数据新增情况 , 如图 5 - 17 所示 .
图 5 - 17 数据表index_personinfo
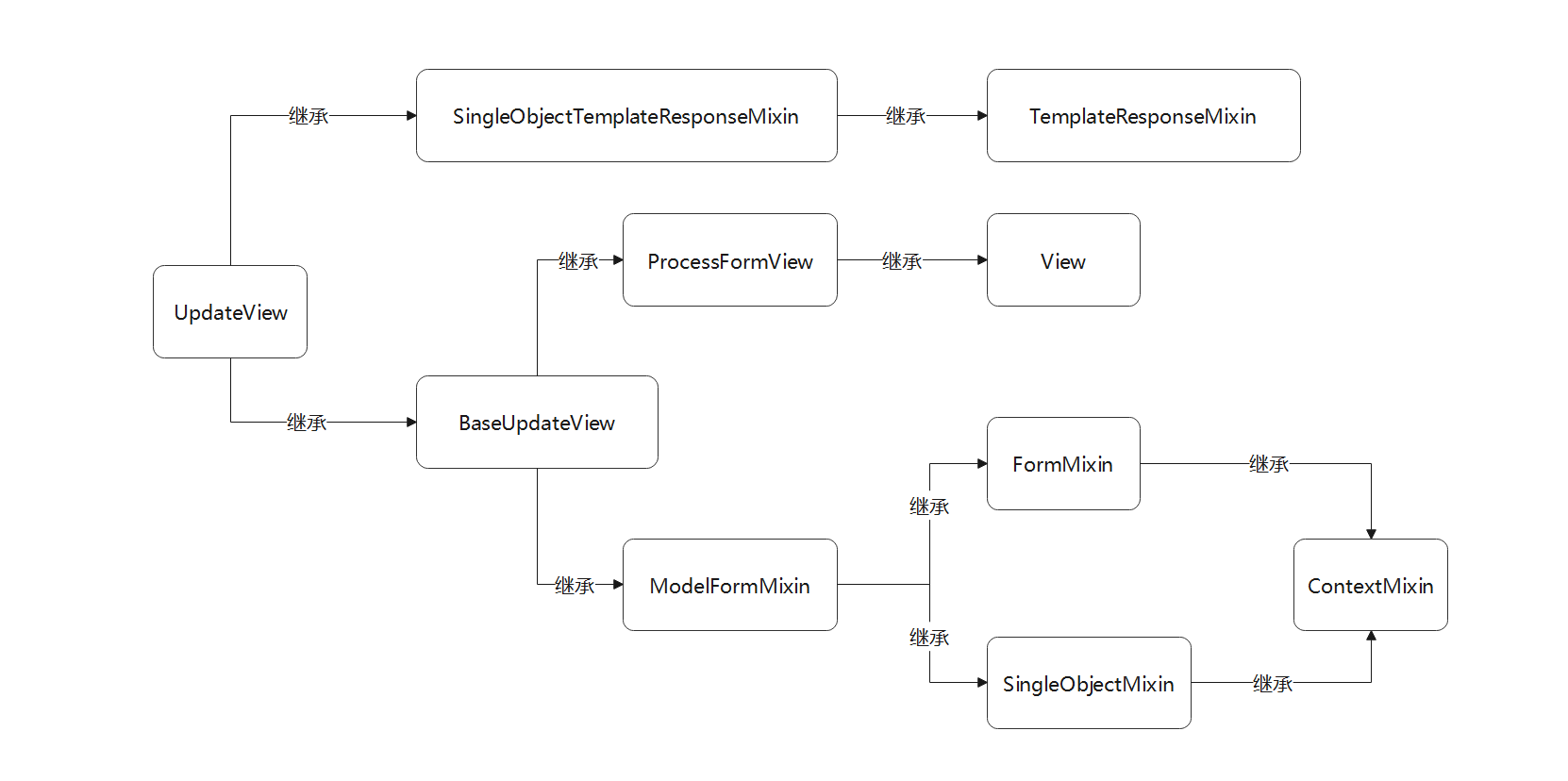
视图类UpdateView是在视图类FormView和视图类DetailView的基础上实现的 ,
它首先使用视图类DetailView的功能 ( 功能核心类是SingleObjectMixin ) ,
通过路由变量查询数据表某条数据并显示在网页上 , 然后在视图类FormView的基础上 , 通过表单方式实现数据修改 .
视图类UpdateView与FormView是在同一个源码文件里定义的 ,
在源码文件里分析视图类UpdateView的定义过程 , 以流程图的形式表示类的继承关系 , 如图 5 - 18 所示 .
图 5 - 18 视图类UpdateView的继承关系
从上述的继承关系发现 , 视图类UpdateView与CreateView的继承关系十分相似 ,
只不过两者的运行过程有所不同 , 从而导致功能上有所差异 .
视图类UpdateView的属性和方法主要来自视图类DetailView , ModelFormMixin和FormMixin ,
这些属性和方法分别在 5.1 .4 小节 , 5.2 .1 小节和 5.2 .2 小节介绍过了 .
以MyDjango为例 , 数据库文件db . sqlite3沿用 5.2 .2 小节的数据 ,
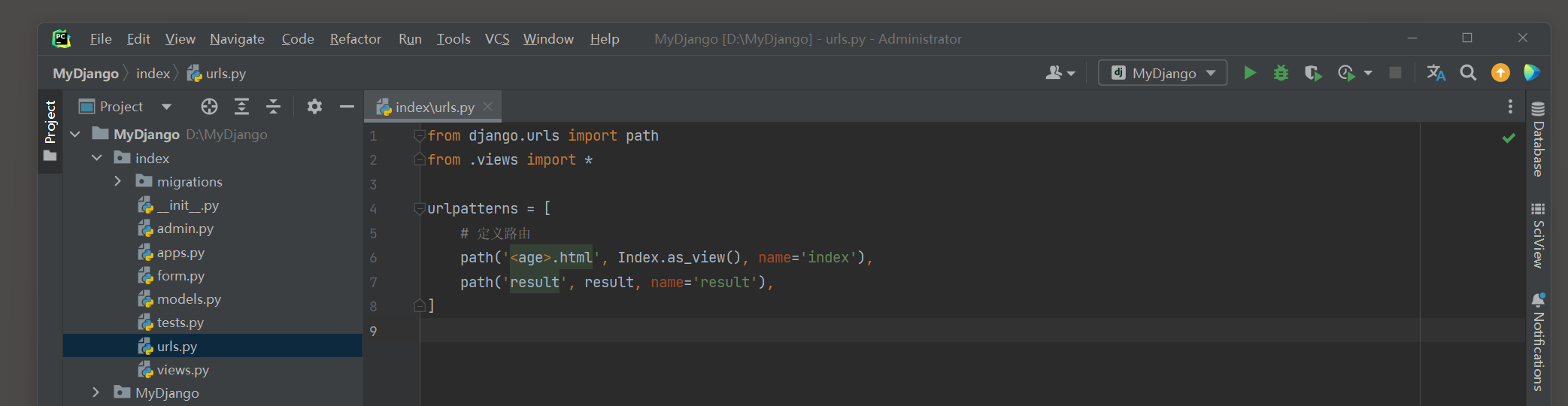
在index的urls . py , views . py和模板文件index . html中分别编写以下代码 :
from django. urls import path
from . views import *
urlpatterns = [
path( '<age>.html' , Index. as_view( ) , name= 'index' ) ,
path( 'result' , result, name= 'result' ) ,
]
from django. views. generic. edit import UpdateView
from . models import PersonInfo
from django. http import HttpResponse
def result ( request) :
return HttpResponse( 'Success' )
class Index ( UpdateView) :
template_name = 'index.html'
success_url = '/result'
model = PersonInfo
fields = [ 'name' , 'age' ]
slug_url_kwarg = 'age'
slug_field = 'age'
extra_context = { 'title' : '人员信息表' }
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> < body> < h3> </ h3> < formmethod = " post" > < inputtype = " submit" value = " 确定" > </ form> </ body> </ html>
视图类index一共设置了 8 个属性 , 这些属性主要来自类TemplateResponseMixin ,
SingleObjectMixin , FormMixin和ModelFormMixin , 这是实现视图类UpdateView的核心功能类 .
路由index的变量age对应视图类index的属性slug_url_kwarg , 用于对模型字段age进行数据筛选 .
筛选结果将会生成表单form和personinfo对象 , 表单form是由类FormMixin的get_context_data ( ) 生成的 ,
personinfo对象则由类SingleObjectMixin的get_context_data ( ) 生成 , 两者的数据都是来自模型PersonInfo .
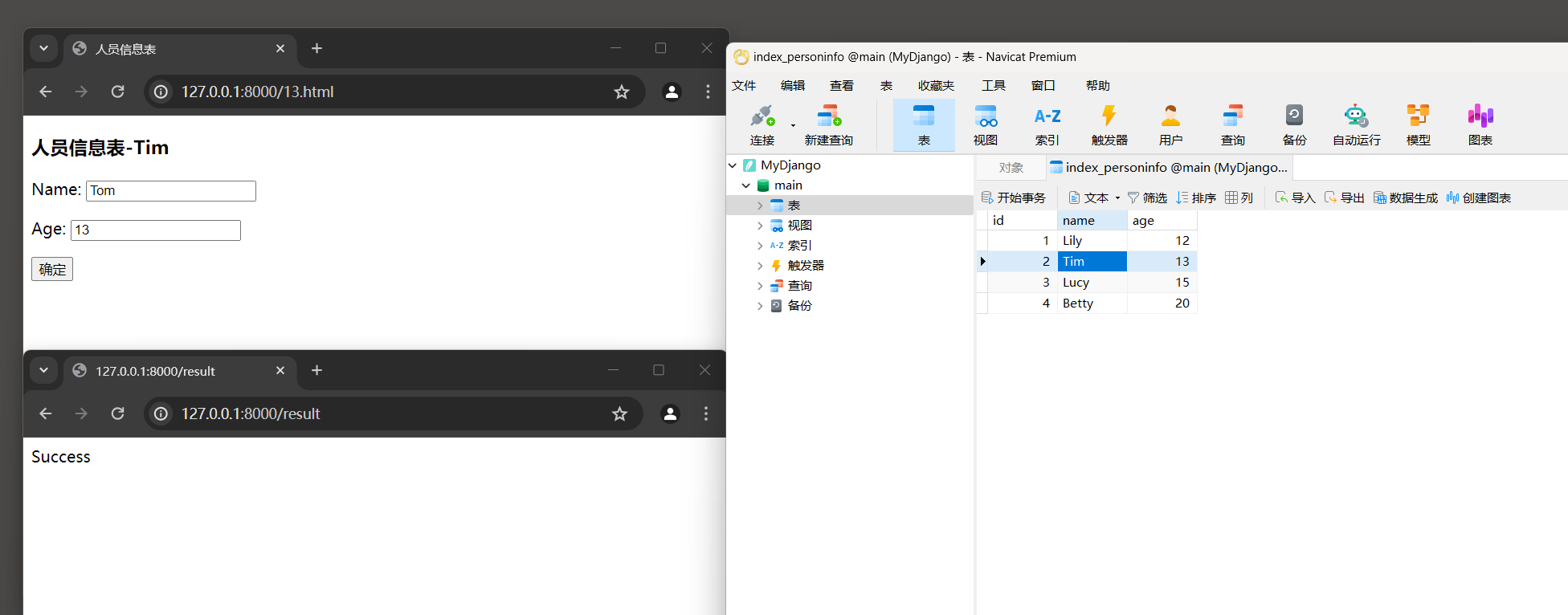
运行MyDjango项目 , 在浏览器上访问 : 127.0 .0 .1 : 8000 / 13. html ,
其中路由地址的 13 代表数据表index_personinfo的字段age等于 13 的数据 , 如图 5 - 19 所示 .
在网页上将表单name改为Tim并单击 '确定' 按钮 , 在数据表index_personinfo中查看字段age等于 13 的数据变化情况 , 如图 5 - 19 所示 .
( slug_url_kwarg设置检索的字段值必须是唯一 , 否则会报错 , 不要修改age ! ! ! )
图 5 - 19 数据表index_personinfo
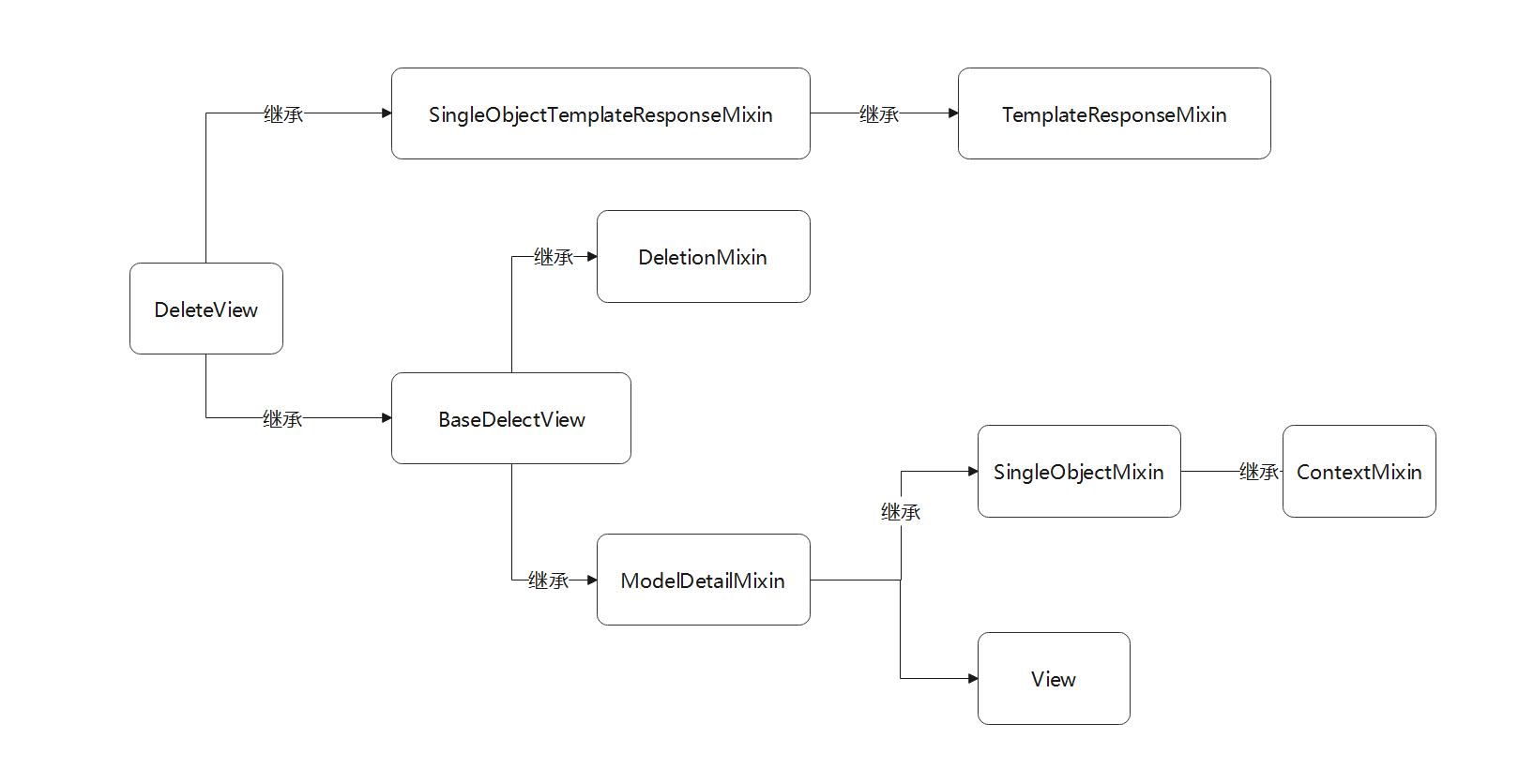
视图类DeleteView的使用方法与视图类UpdateView有相似之处 , 但两者的父类继承关系有所差异 .
在源码文件里分析视图类DeleteView的定义过程 , 以流程图的形式表示类的继承关系 , 如图 5 - 20 所示 .
图 5 - 20 视图类DeleteView的继承关系
视图类DeleteView只能删除单条数据 , 路由变量为模型主键提供查询范围 ,
因为模型主键具有唯一性 , 所以通过主键查询能精准到某条数据 .
查询出来的数据通过POST请求实现数据删除 , 删除过程由类DeletionMixin的delete ( ) 方法完成 .
视图类DeleteView的属性与方法主要来自类SingleObjectMixin ,
DeletionMixin和TemplateResponseMixin , 每个属性与方法的作用不再重复讲述 .
以MyDjango为例 , 数据库文件db . sqlite3沿用 5.2 .3 小节的数据 ,
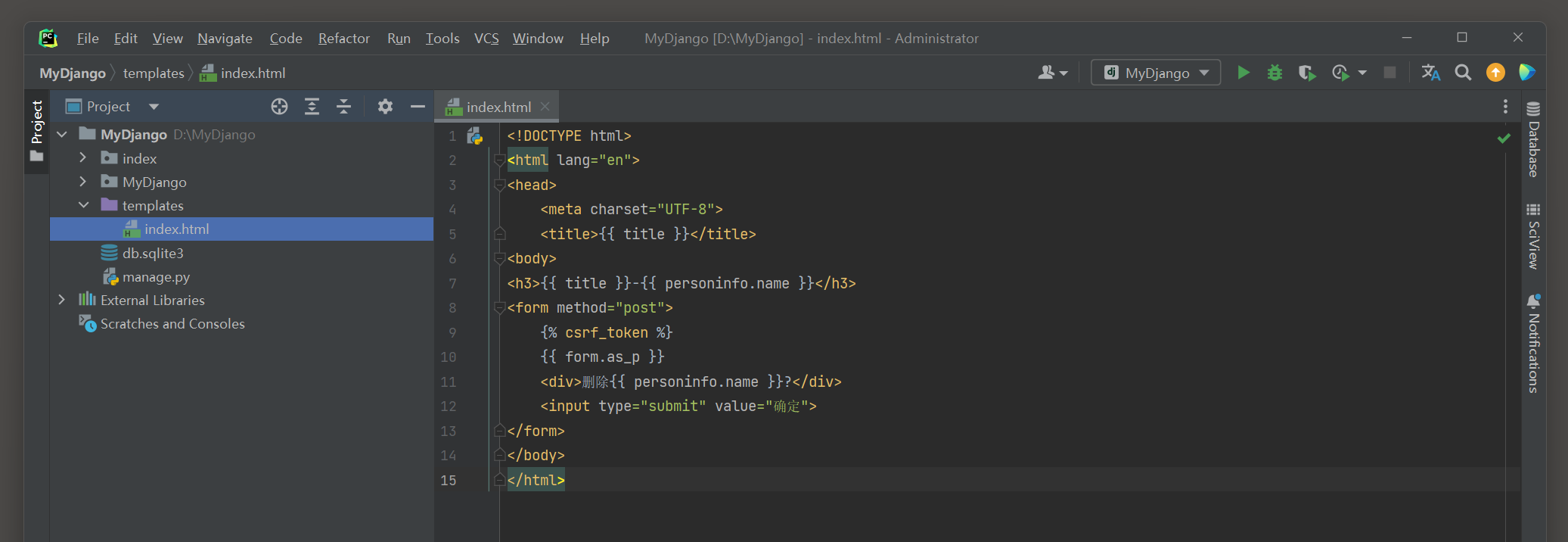
在index的urls . py , views . py和模板文件index . html中分别编写以下代码 :
from django. urls import path
from . views import *
urlpatterns = [
path( '<pk>.html' , Index. as_view( ) , name= 'index' ) ,
path( 'result' , result, name= 'result' ) ,
]
from django. views. generic. edit import DeleteView
from . models import PersonInfo
from django. http import HttpResponse
def result ( request) :
return HttpResponse( 'Success' )
class Index ( DeleteView) :
template_name = 'index.html'
success_url = '/result'
model = PersonInfo
context_object_name = 'personinfo'
extra_context = { 'title' : '人员信息表' }
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> < body> < h3> </ h3> < formmethod = " post" > < div> </ div> < inputtype = " submit" value = " 确定" > </ form> </ body> </ html>
路由index设置变量pk , 对应视图类index的属性pk_url_kwarg , 该属性的默认值为pk , 默认值的设定可以在类SingleObjectMixin中找到 .
视图类index会根据路由变量pk的值在数据表index_personinfo里找到相应的数据信息 , 查找过程由类BaseDetailView完成 .
模板上下文不再生成表单对象form , 只有personinfo对象 , 该对象由类SingleObjectMixin的get_context_data ( ) 生成 .
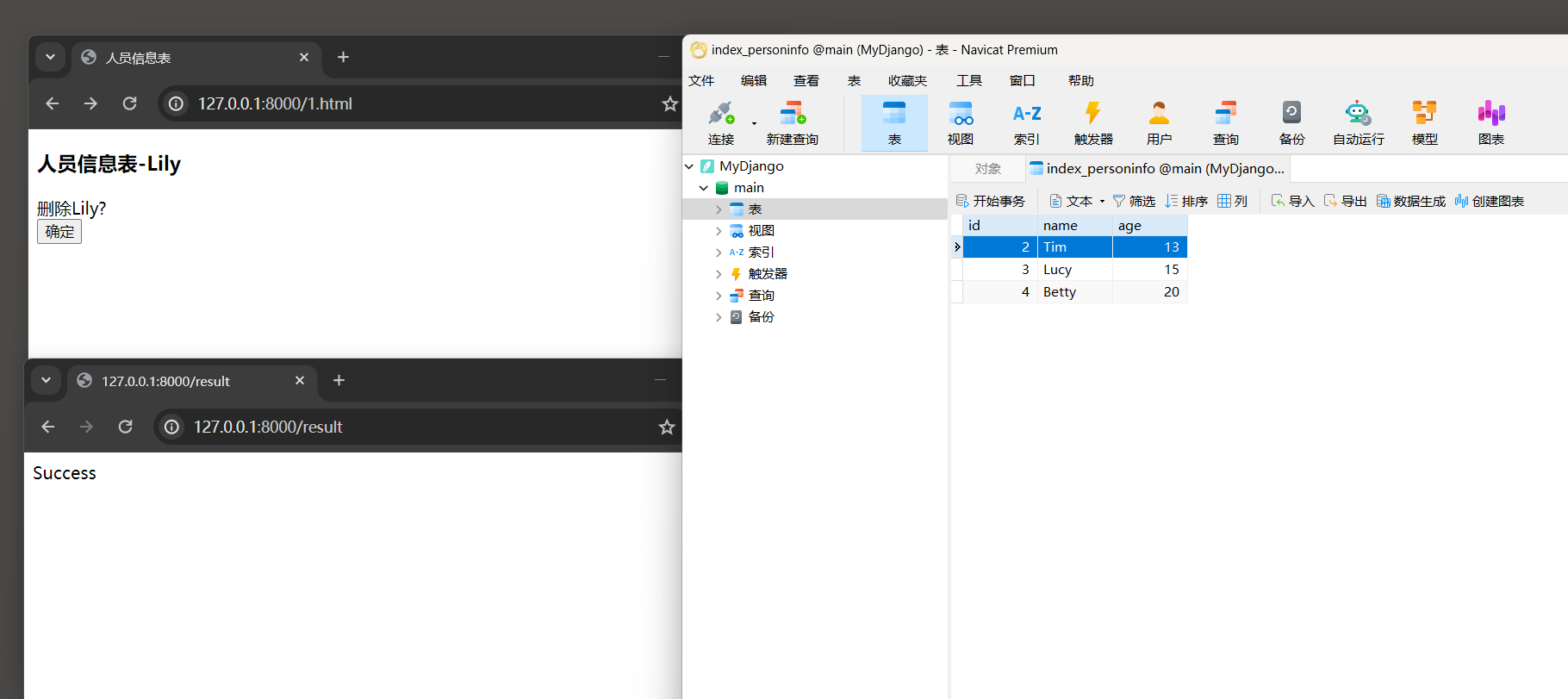
运行MyDjango项目 , 在浏览器上访问 : 127.0 .0 .1 : 8000 / 1. html ,
路由地址的 1 代表数据表index_personinfo的主键id等于 1 的数据 , 如图 5 - 17 所示 .
在网页上单击 '确定' 按钮即可删除该数据 , 在数据表index_personinfo中查看主键id等于 1 的数据是否存在 , 如图 5 - 21 所示 .
图 5 - 21 数据表index_personinfo
日期筛选视图是根据模型里的某个日期字段进行数据筛选的 , 然后将符合结果的数据以一定的形式显示在网页上 .
简单来说 , 在列表视图ListView或详细视图DetailView的基础上增加日期筛选所实现的视图类 .
它一共定义了 7 个日期视图类 , 说明如下 :
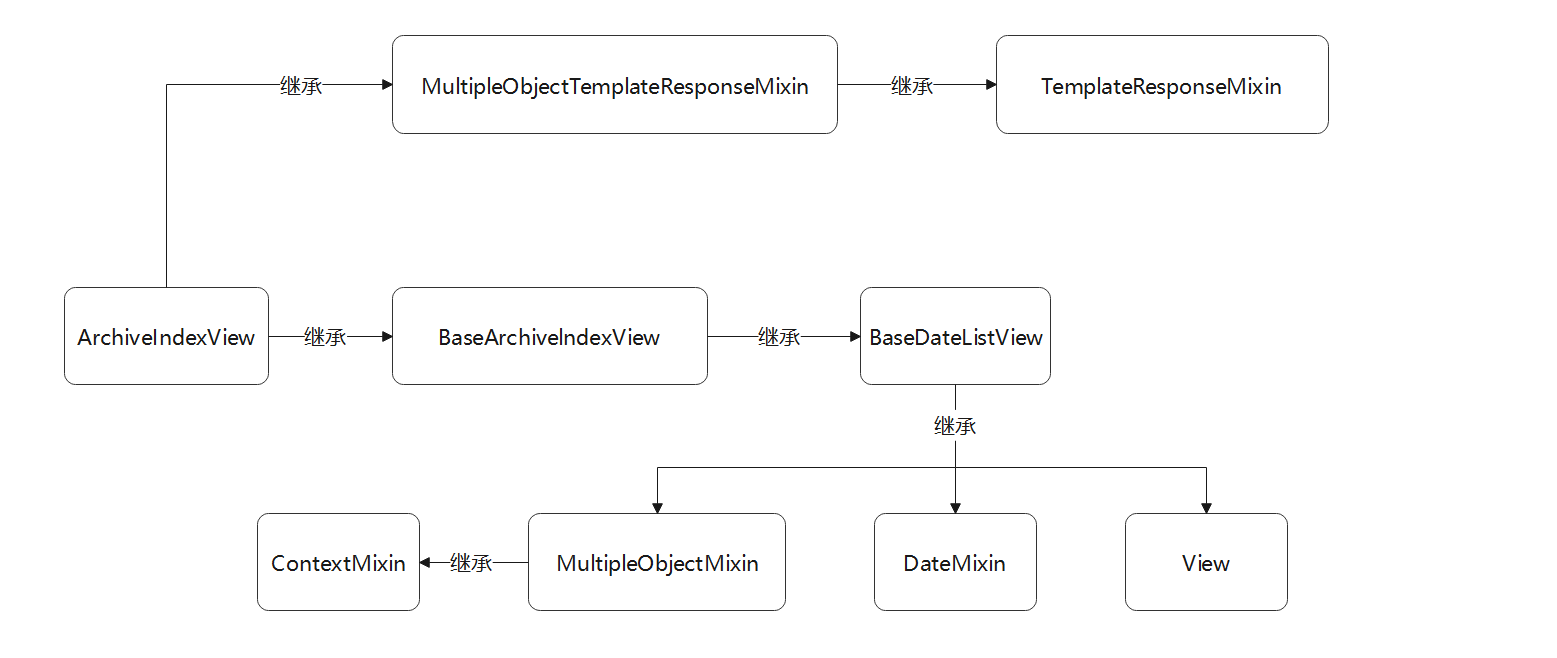
● ArchiveIndexView是将数据表所有的数据以某个日期字段的降序方式进行排序显示的 .
该类的继承关系如图 5 - 22 所示 .
图 5 - 22 视图类ArchiveIndexView的继承关系
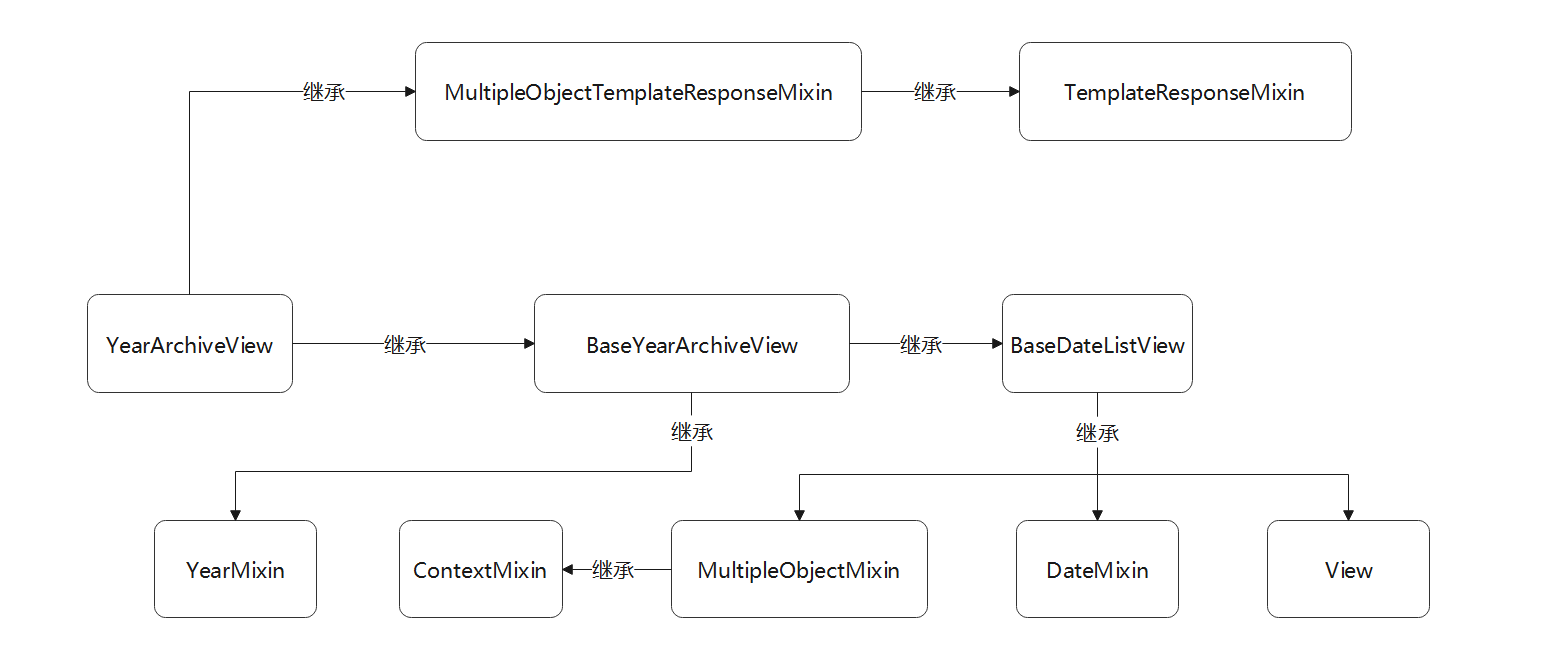
● YearArchiveView是在数据表筛选某个日期字段某年的所有的数据 , 默认以升序的方式排序显示 , 年份的筛选范围由路由变量提供 .
该类的继承关系如图 5 - 23 所示 .
图 5 - 23 视图类YearArchiveView的继承关系
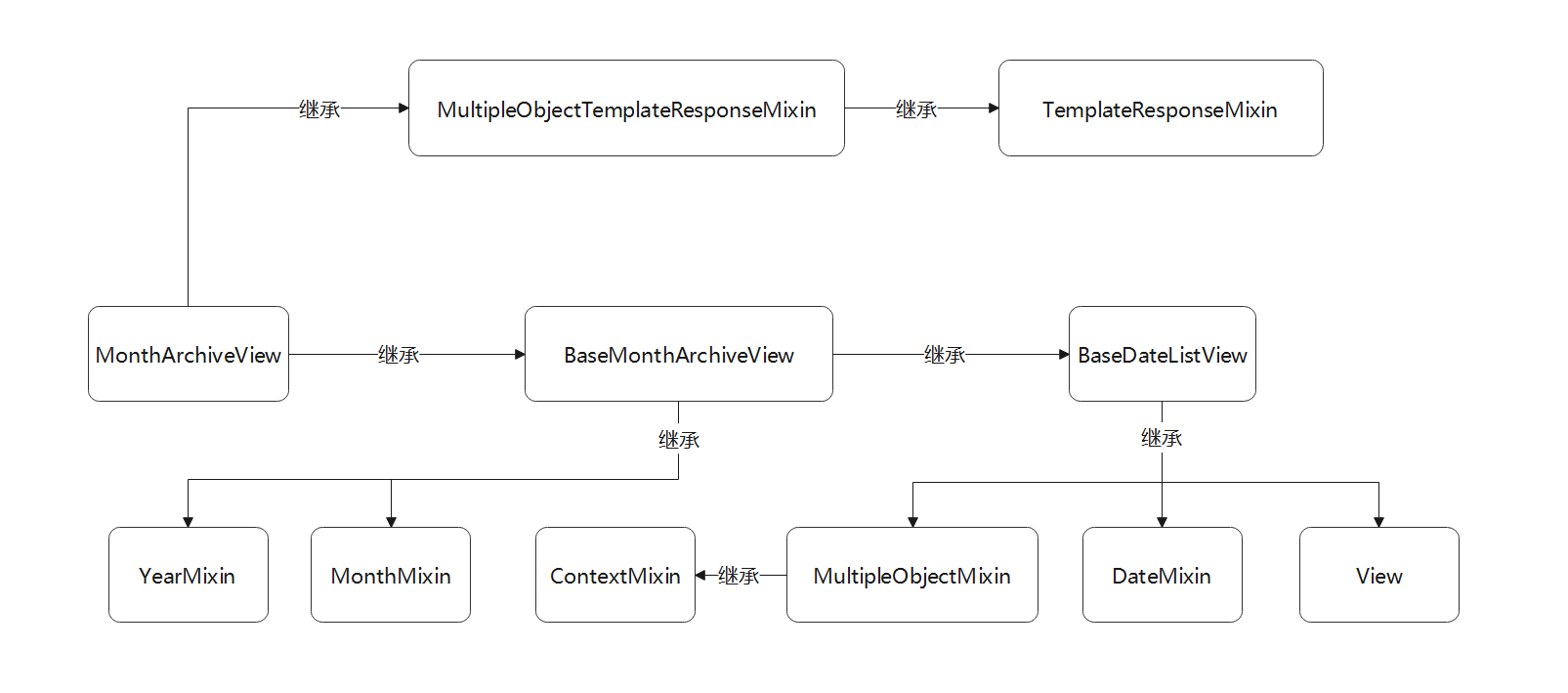
● MonthArchiveView是在数据表筛选某个日期字段某年某月的所有的数据 , 默认以升序的方式排序显示 ,
年份和月份的筛选范围都由路由变量提供 . 该类的继承关系如图 5 - 24 所示 .
图 5 - 24 视图类MonthArchiveView的继承过程
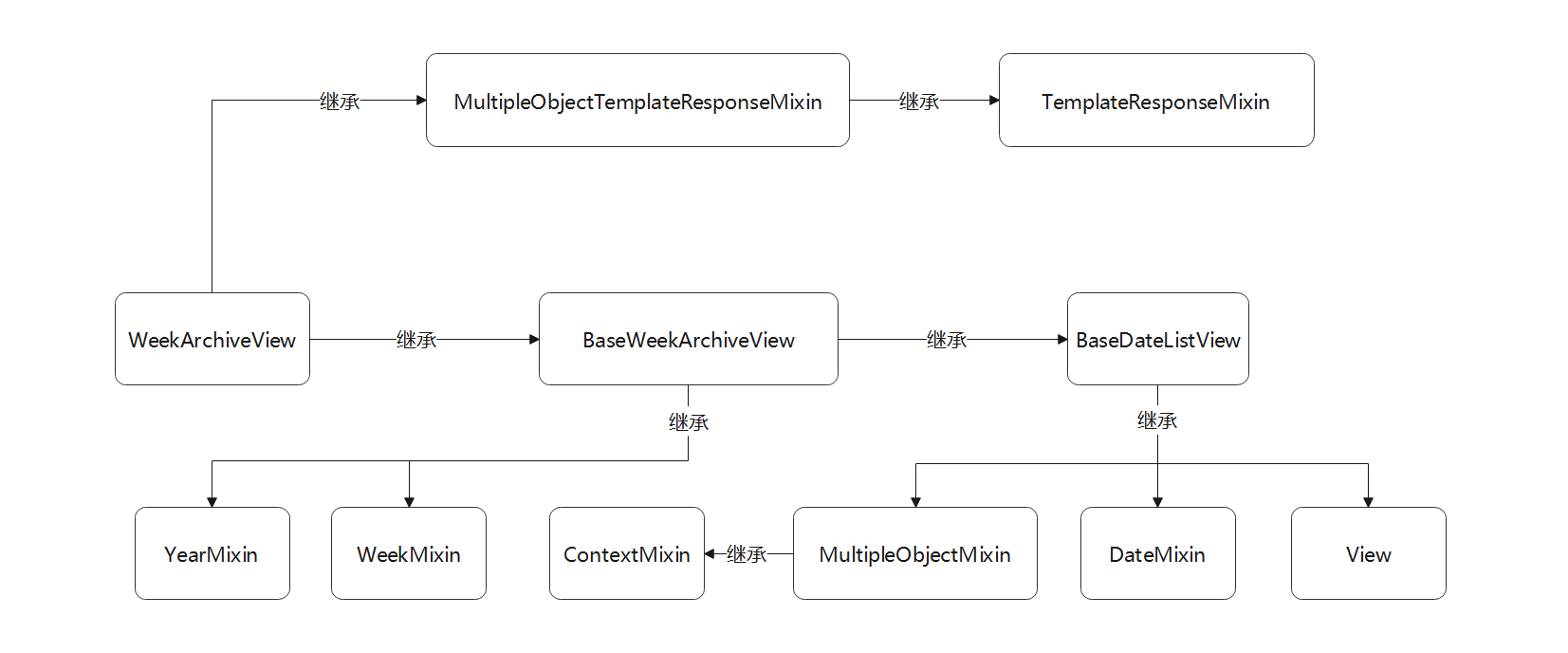
● WeekArchiveView是在数据表筛选某个日期字段某年某周的所有的数据 ,
总周数是将一年的总天数除以 7 所得的 , 数据默认以升序的方式排序显示 , 年份和周数的筛选范围都是由路由变量提供的 .
该类的继承关系如图 5 - 25 所示 .
图 5 - 25 视图类WeekArchiveView的继承关系
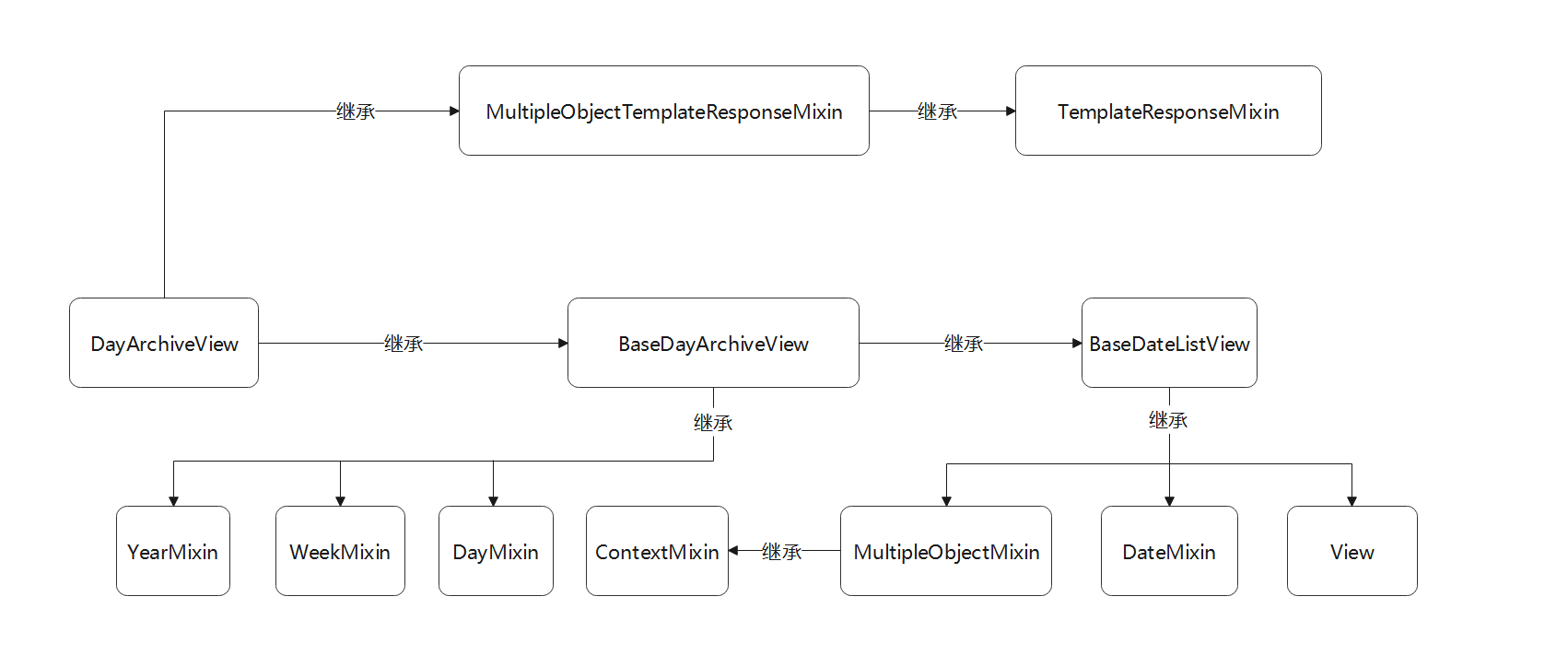
● DayArchiveView是对数据表的某个日期字段精准筛选到某年某月某天 ,
将符合条件的数据以升序的方式排序显示 , 年份 , 月份和天数都是由路由变量提供的 .
该类的继承关系如图 5 - 26 所示 .
图 5 - 26 视图类DayArchiveView的继承关系
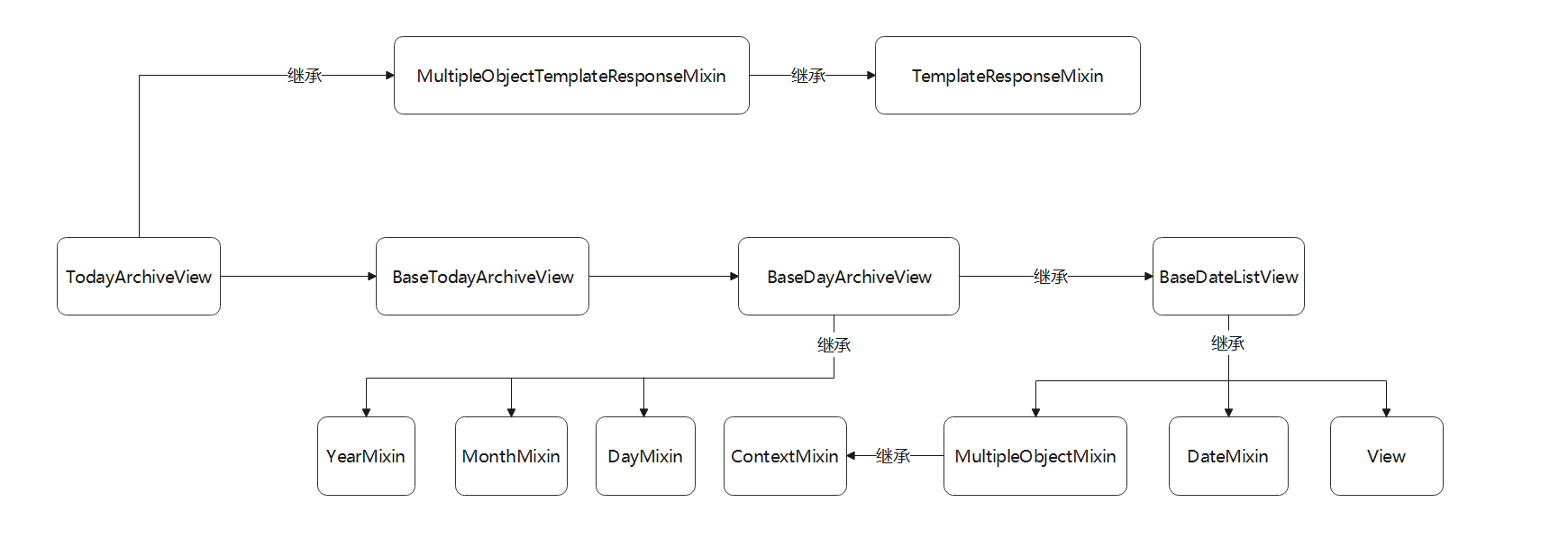
● TodayArchiveView是在视图类DayArchiveView的基础上进行封装处理的 ,
它将数据表某个日期字段的筛选条件设为当天时间 , 符合条件的数据以升序的方式排序显示 .
该类的继承关系如图 5 - 27 所示 .
图 5 - 27 视图类TodayArchiveView的继承关系
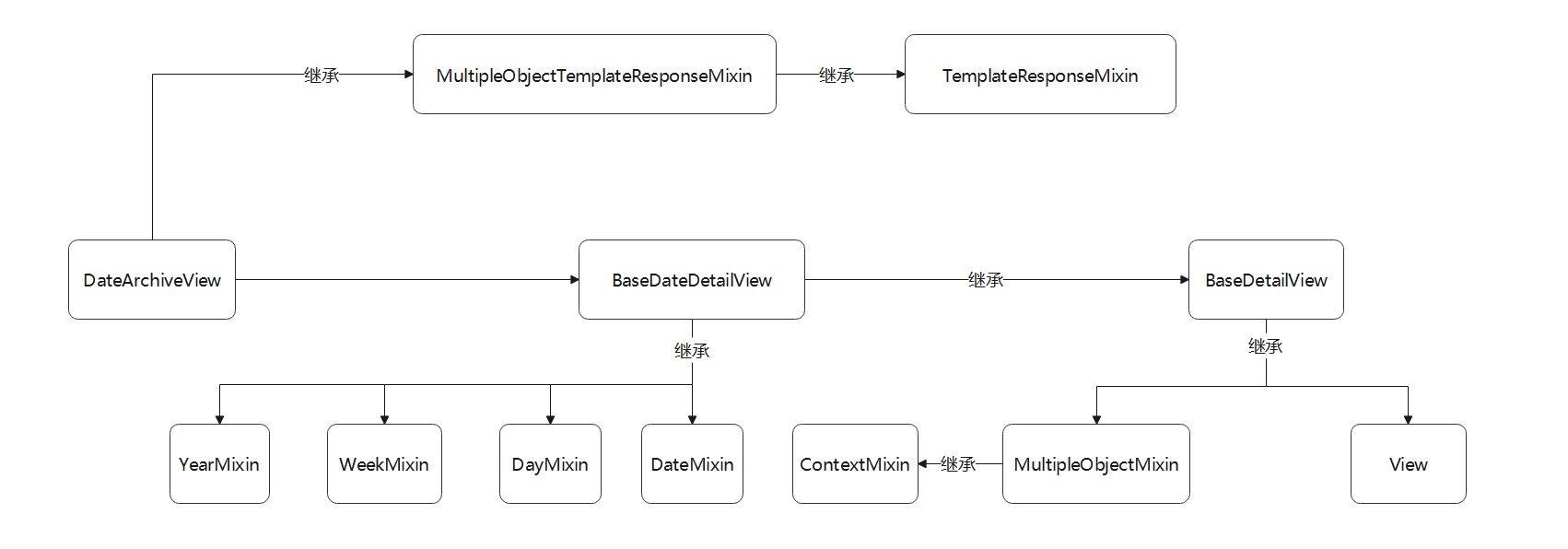
● DateDetailView是查询某年某月某日某条数据的详细信息 ,
它在视图类DetailView的基础上增加了日期筛选功能 , 筛选条件主要有年份 , 月份 , 天数和某个模型字段 ,
其中某个模型字段必须具有唯一性 , 才能确保查询的数据具有唯一性 .
该类的继承关系如图 5 - 28 所示 .
从日期筛选视图类的继承关系得知 , 它们的继承关系都有一定的相似之处 , 说明它们的属性和方法在使用上不会存在太大的差异 .
因此 , 我们选择最有代表性的视图类MonthArchiveView和WeekArchiveView进行讲述 ,
在日常开发中 , 这两个日期视图类通常用于开发报表功能 ( 月报表和周报表 ) .
本节来了解视图类MonthArchiveView的继承过程 ,
类MultipleObjectMixin的属性和方法在 5.1 .3 小节已经详细讲述过了 , 本小节不再重复列举 .
此外 , 视图类MonthArchiveView新增的属性和方法说明如下 :
● template_name_suffix : 由MonthArchiveView定义 , 设置模板后缀名 , 用于设置默认模板文件 .
● date_list_period : 由BaseDateListView定义 , 经BaseMonthArchiveView重写 , 设置日期列表的最小单位 , 默认值为day .
● get_dated_items ( ) : 由BaseDateListView定义 , 经BaseMonthArchiveView重写 , 根据年份和月份在数据表查询符合条件的数据 .
● year_format : 由YearMixin定义 , 设置年份的数据格式 , 即路由变量的数据格式 , 默认值为 % Y , 代表数字年份 , 如 2019.
● year : 由YearMixin定义 , 设置默认查询的年份 , 如果没有设置属性值 , 就从路由变量year里获取 , 默认值为None .
● get_year_format ( ) : 由YearMixin定义 , 获取属性year_format的属性值 .
● get_year ( ) : 由YearMixin定义 , 获取属性year的属性值 .
● get_next_year ( ) : 由YearMixin定义 , 获取下一年的年份 .
● get_previous_year ( ) : 由YearMixin定义 , 获取上一年的年份 .
● _get_next_year ( ) : 由YearMixin定义的受保护方法 , 获取下一年的年份 .
● _get_current_year : 由YearMixin定义的受保护方法 , 获取当前的年份 .
● month_format : 由MonthMixin定义 , 设置月份的数据格式 , 即路由变量的数据格式 , 默认值为 % b , 代表月份英文前 3 个字母 , 如Sep .
● month : 由MonthMixin定义 , 设置查询的月份 , 默认值为None .
● get_month_format ( ) : 由MonthMixin定义 , 获取属性month_format的属性值 .
● get_month ( ) : 由MonthMixin定义 , 获取属性month的属性值 .
● get_next_month ( ) : 由MonthMixin定义 , 获取下个月的月份 .
● get_previous_month ( ) : 由MonthMixin定义 , 获取上个月的月份 .
● _get_next_month ( ) : 由MonthMixin定义的受保护方法 , 获取下个月的月份 .
● _get_current_month ( ) : 由MonthMixin定义的受保护方法 , 获取当前的月份 .
● allow_empty : 由BaseDateListView定义 , 数据类型为布尔型 ,
在模型中查询数据不存在的情况下是否显示页面 , 若为False并且数据不存在 , 则引发 404 异常 , 默认值为False .
● get ( ) : 由BaseDateListView定义 , 定义HTTP请求的GET请求处理 .
● get_ordering ( ) : 由BaseDateListView定义 , 确定排序方式 ,
默认值是以日期字段排序 , 若设置类MultipleObjectMixin的属性ordering , 则以属性ordering进行排序 .
● get_dated_queryset ( ) : 由BaseDateListView定义 , 根据属性allow_future和allow_empty设置日期条件 .
● get_date_list_period ( ) : 由BaseDateListView定义 , 获取date_list_period的属性值 .
● get_date_list ( ) : 由BaseDateListView定义 , 根据日期条件在数据表里查找相符的数据列表 .
● date_field : 由DateMixin定义 , 默认值为None , 设置模型的日期字段 , 通过该字段对数据表进行查询筛选 .
● allow_future : 由DateMixin定义 , 默认值为None , 设置是否显示未来日期的数据 , 如产品有效期 .
● get_date_field ( ) : 由DateMixin定义 , 获取属性date_field的属性值 .
● get_allow_future ( ) : 由DateMixin定义 , 获取属性allow_future的属性值 .
● uses_datetime_field ( ) : 由DateMixin定义 , 判断字段是否为DateTimeField格式 , 并根据判断结果返回True或False .
● _make_date_lookup_arg ( ) : 由DateMixin定义的受保护方法 , 根据uses_datetime_field ( ) 判断结果是否执行日期格式转换 .
● _make_single_date_lookup ( ) : 由DateMixin定义的受保护方法 , 根据uses_datetime_field ( ) 判断结果设置日期的查询条件 .
以上从源码角度分析了视图类MonthArchiveView的属性和方法 ,
下一步从项目开发的角度来讲述如何使用视图类MonthArchiveView实现数据筛选功能 .
以MyDjango为例 , 首先将index的models . py重新定义 , 在模型PersonInfo里增设日期字段hireDate , 代码如下 :
from django. db import models
class PersonInfo ( models. Model) :
id = models. AutoField( primary_key= True )
name = models. CharField( max_length= 20 )
age = models. IntegerField( )
hireDate = models. DateField( )
模型PersonInfo定义完成后 , 将index的migrations文件夹的 0001 _initial . py删除 ,
同时使用Navicat Premium打开数据库文件db . sqlite3 , 将数据库所有的数据表删除 ,
接着在PyCharm的Terminal选项卡里依次输入数据迁移指令 .
D: \MyDjango> python manage. py makemigrations
Migrations for 'index' :
index\migrations\0001_initial. py
- Create model personinfo
D: \MyDjango> python manage. py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations:
Applying contenttypes. 0001_initial. . . OK
Applying auth. 0001_initial. . . OK
Applying admin. 0001_initial. . . OK
Applying admin. 0002_logentry_remove_auto_add. . . OK
Applying admin. 0003_logentry_add_action_flag_choices. . . OK
Applying contenttypes. 0002_remove_content_type_name. . . OK
Applying auth. 0002_alter_permission_name_max_length. . . OK
Applying auth. 0003_alter_user_email_max_length. . . OK
Applying auth. 0004_alter_user_username_opts. . . OK
Applying auth. 0005_alter_user_last_login_null. . . OK
Applying auth. 0006_require_contenttypes_0002. . . OK
Applying auth. 0007_alter_validators_add_error_messages. . . OK
Applying auth. 0008_alter_user_username_max_length. . . OK
Applying auth. 0009_alter_user_last_name_max_length. . . OK
Applying auth. 0010_alter_group_name_max_length. . . OK
Applying auth. 0011_update_proxy_permissions. . . OK
Applying auth. 0012_alter_user_first_name_max_length. . . OK
Applying index. 0001_initial. . . OK
Applying sessions. 0001_initial. . . OK
当指令执行完成后 , 再次使用Navicat Premium软件打开db . sqlite3文件 ,
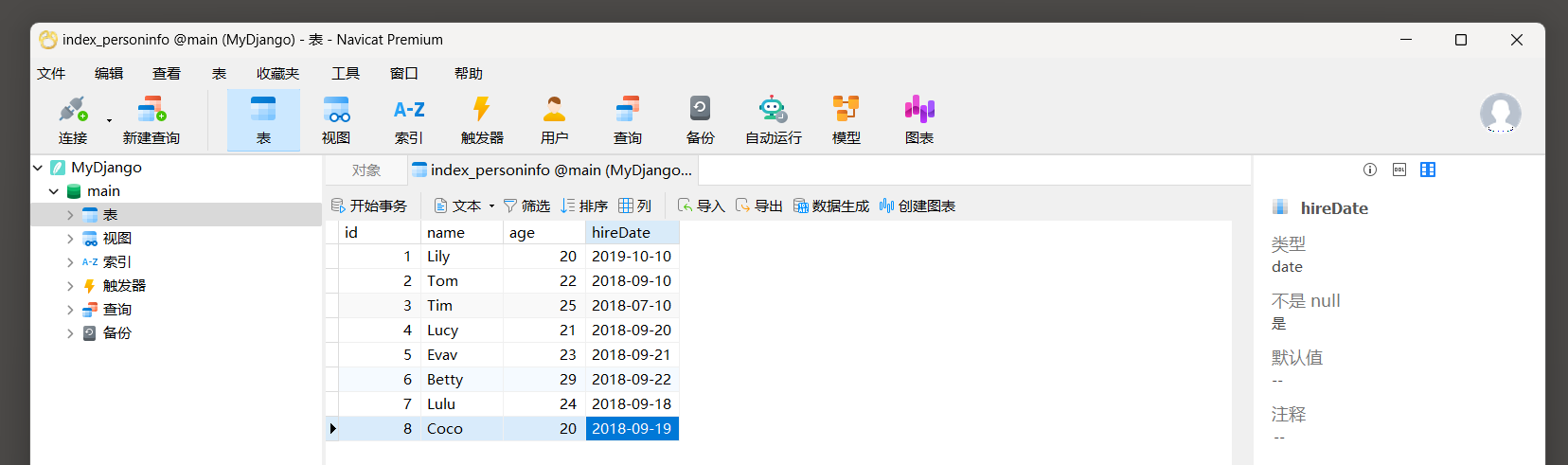
在数据库中可以看到新创建的数据表 , 在数据表index_personinfo中添加数据内容 , 如图 5 - 29 所示 .
图 5 - 29 数据表index_personinfo的数据信息
完成项目环境搭建后 , 接下来使用视图类MonthArchiveView实现数据筛选功能 .
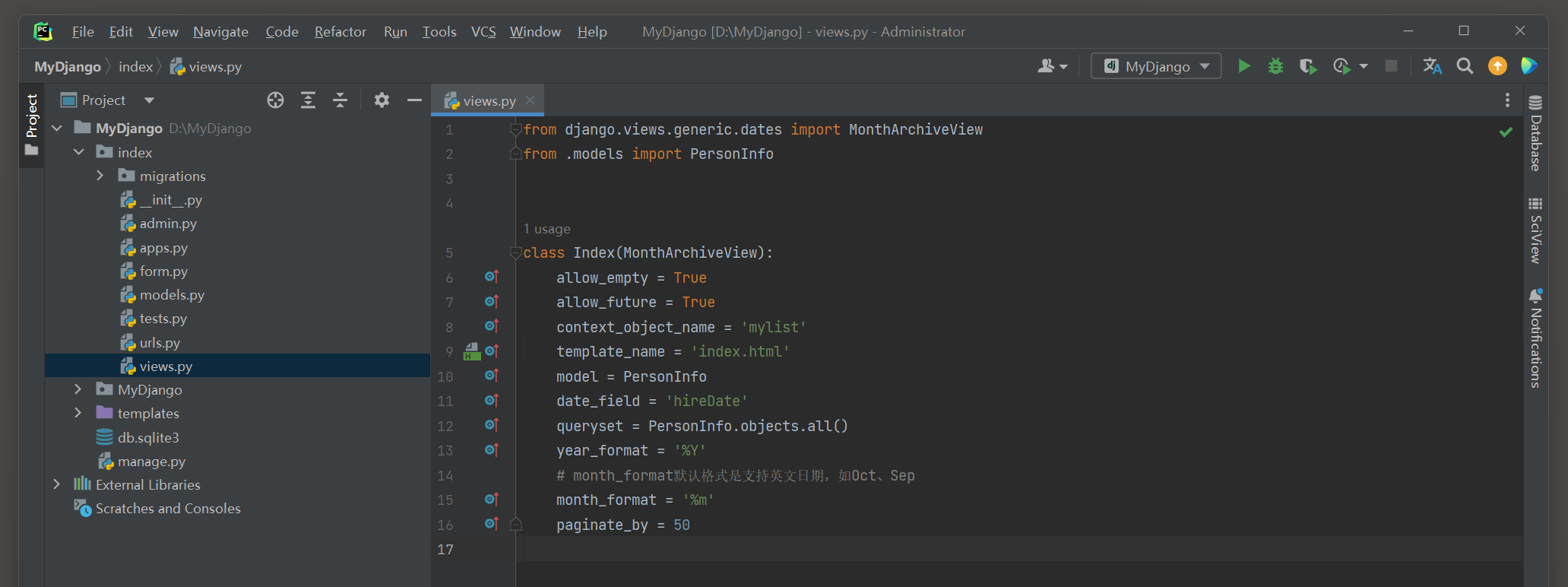
在index的urls . py , views . py和模板文件index . html中分别编写以下代码 :
from django. urls import path
from . views import *
urlpatterns = [
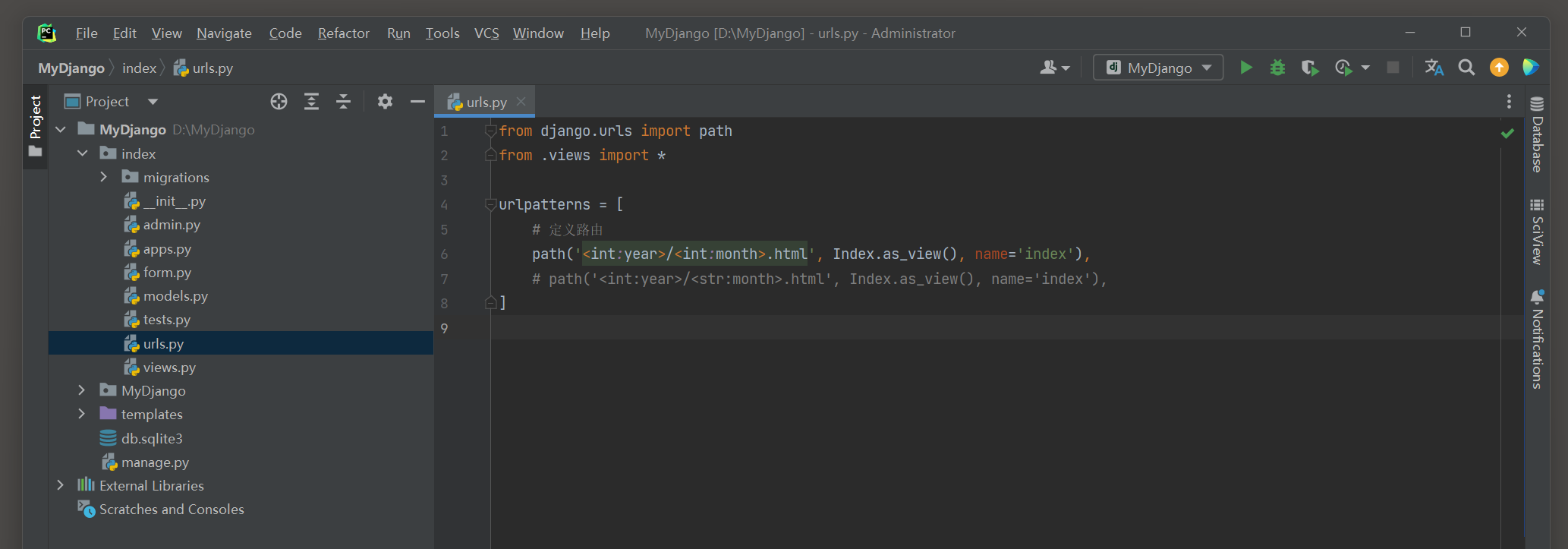
path( '<int:year>/<int:month>.html' , Index. as_view( ) , name= 'index' ) ,
]
from django. views. generic. dates import MonthArchiveView
from . models import PersonInfo
class Index ( MonthArchiveView) :
allow_empty = True
allow_future = True
context_object_name = 'mylist'
template_name = 'index.html'
model = PersonInfo
date_field = 'hireDate'
queryset = PersonInfo. objects. all ( )
year_format = '%Y'
month_format = '%m'
paginate_by = 50
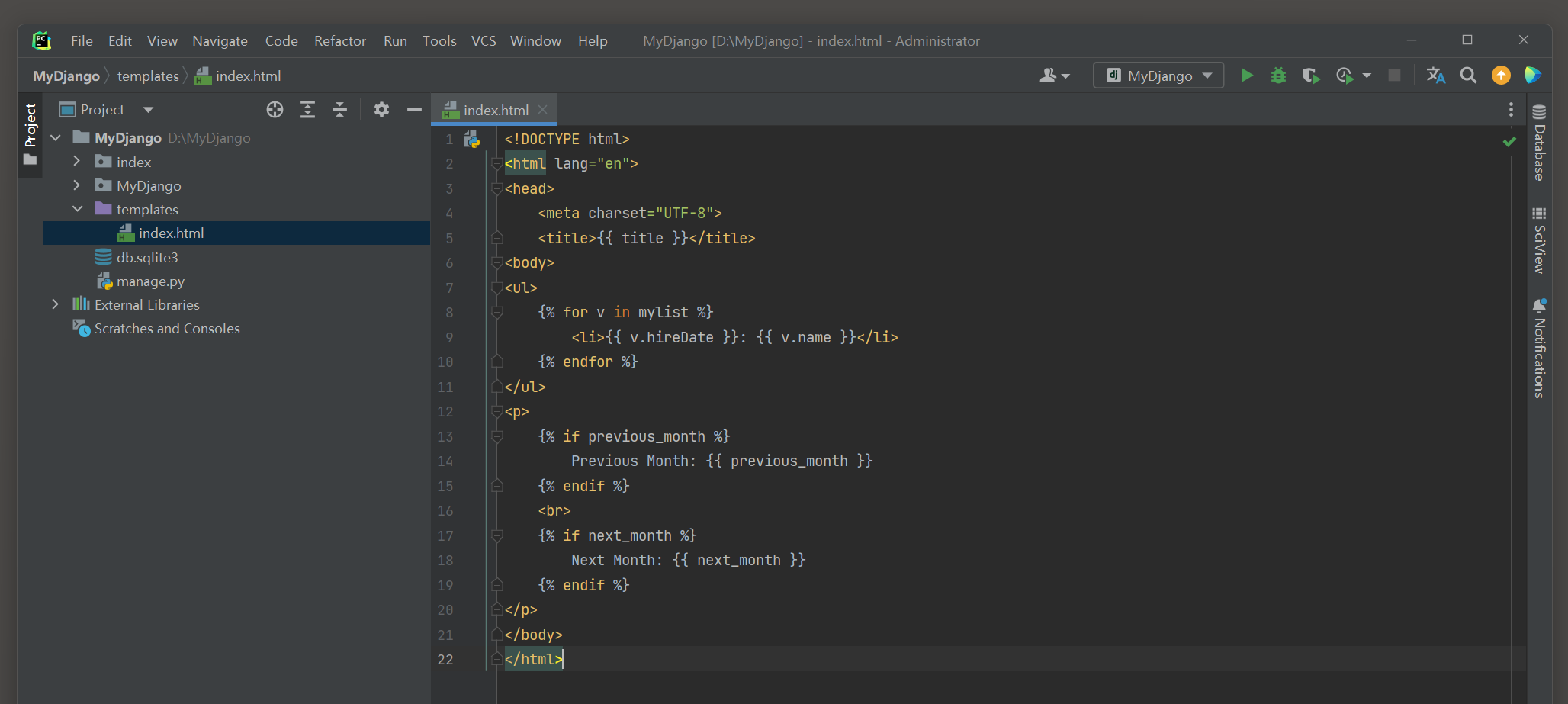
<! DOCTYPE html > < html> < head> < title> </ title> < body> < ul> < li> </ li> </ ul> < p> < br> </ p> </ body> </ html>
路由index在路由地址里设置变量year和month , 而且变量的数据类型都是整型 ,
其中路由变量month可以设为字符型 , 不同的数据类型会影响视图类MonthArchiveView的属性month_format的值 .
视图类index继承父类MonthArchiveView , 它共设置了 10 个属性 , 每个属性已经详细讲述过了 , 在此不再重复说明 .
视图类index是对模型PersonInfo进行数据查找 , 查找方式是以字段hireDate的日期内容进行数据筛选 ,
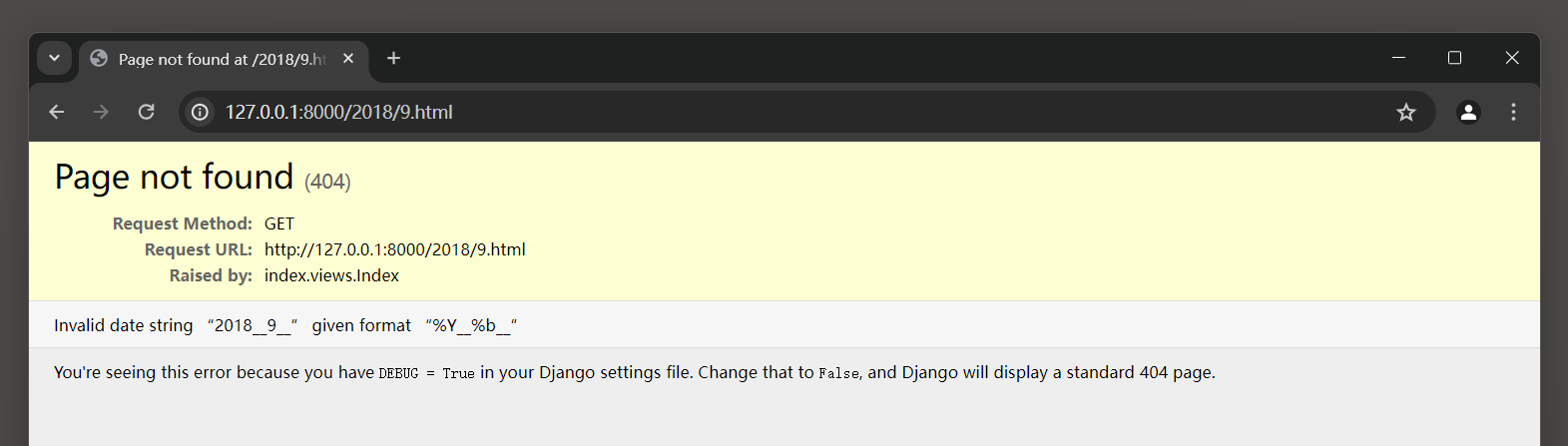
筛选条件来自路由变量year和month , 由于变量month的数据类型是整型 , 因此将属性month_format的默认值 % b改为 % m ,
否则Django会提示 404 异常 , 如图 5 - 30 所示 .
图 5 - 30 异常信息
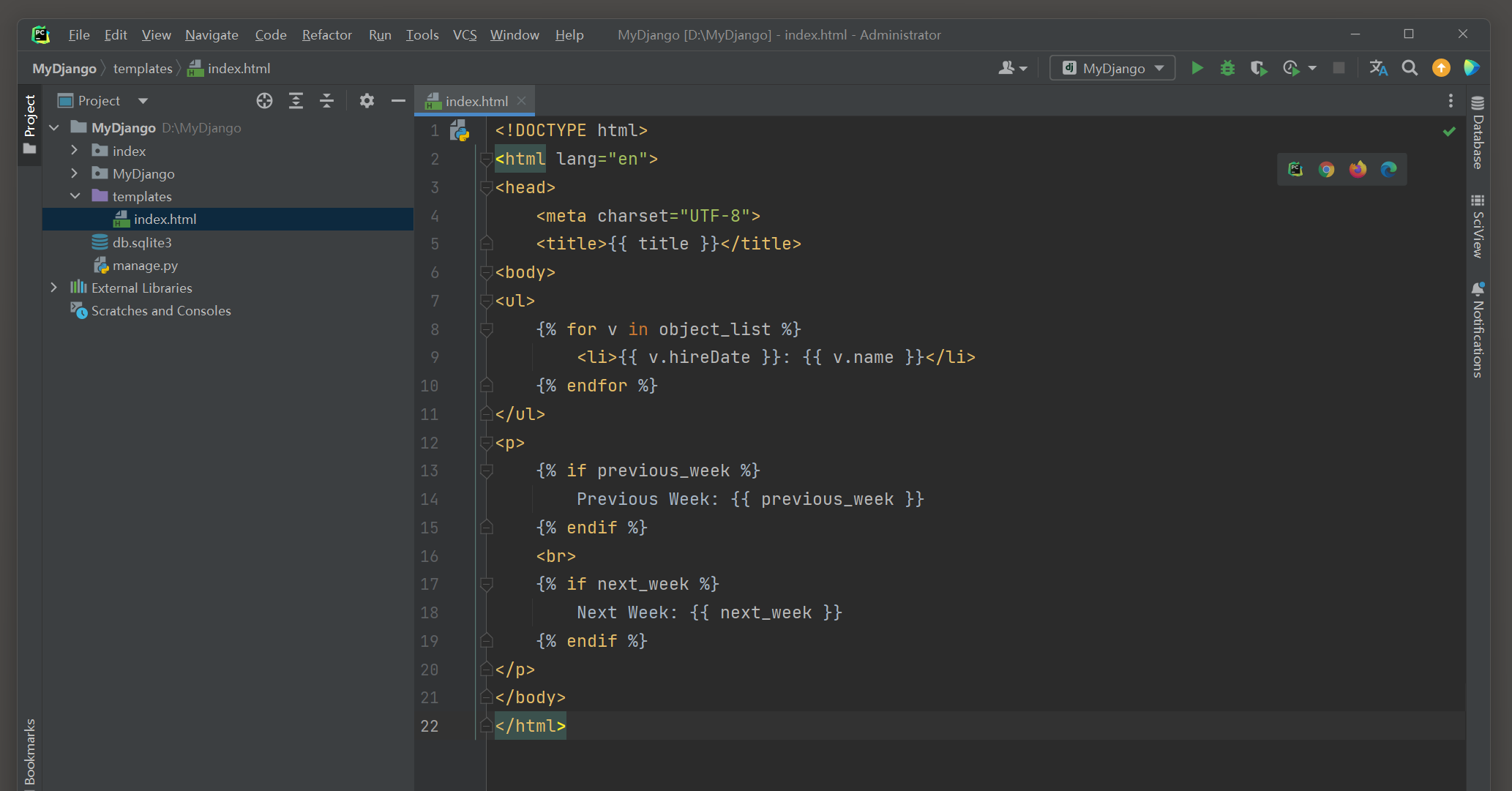
模板文件index . html使用了模板上下文mylist , previous_month和next_month ,
此外 , 视图类MonthArchiveView还设有其他模板上下文 , 具体说明如下 :
● mylist : 这是由模型PersonInfo查询所得的数据对象 , 它的命名是由视图类index的属性context_object_name设置的 ,
如果没设置该属性 , 模板上下文就默认为object_list或者page_obj .
● previous_month : 根据路由变量year和month的日期计算出上一个月的日期 .
● next_month : 根据路由变量year和month的日期计算出下一个月的日期 .
● date_list : 从查询所得的数据里获取日期字段的日期内容 .
● paginator : 由类MultipleObjectMixin生成 , 这是Django内置的分页功能对象 .
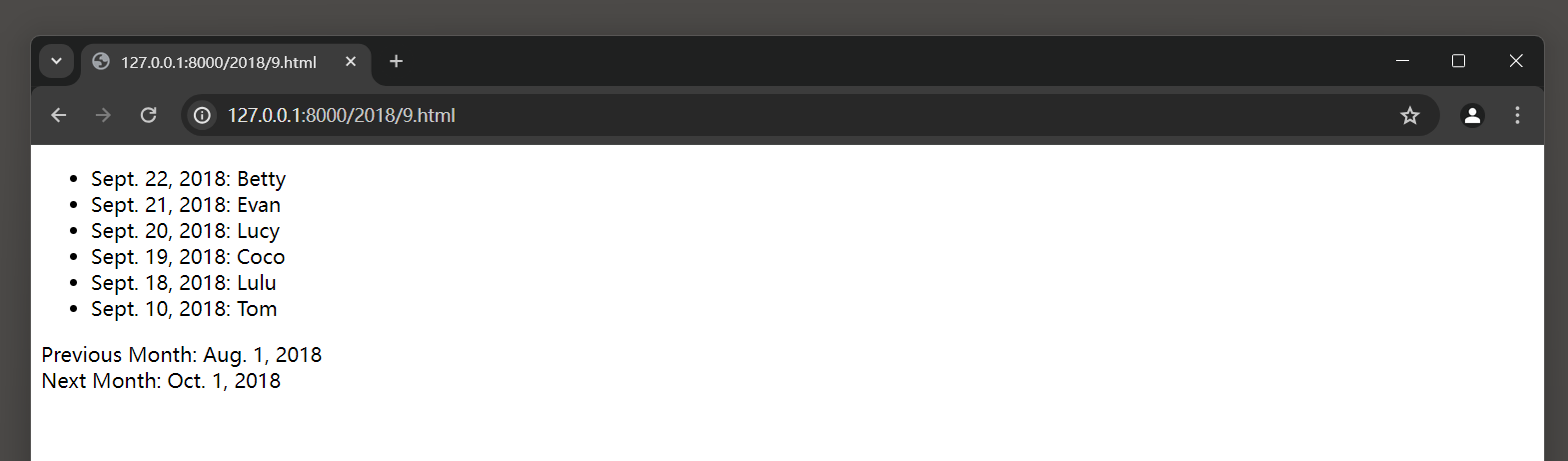
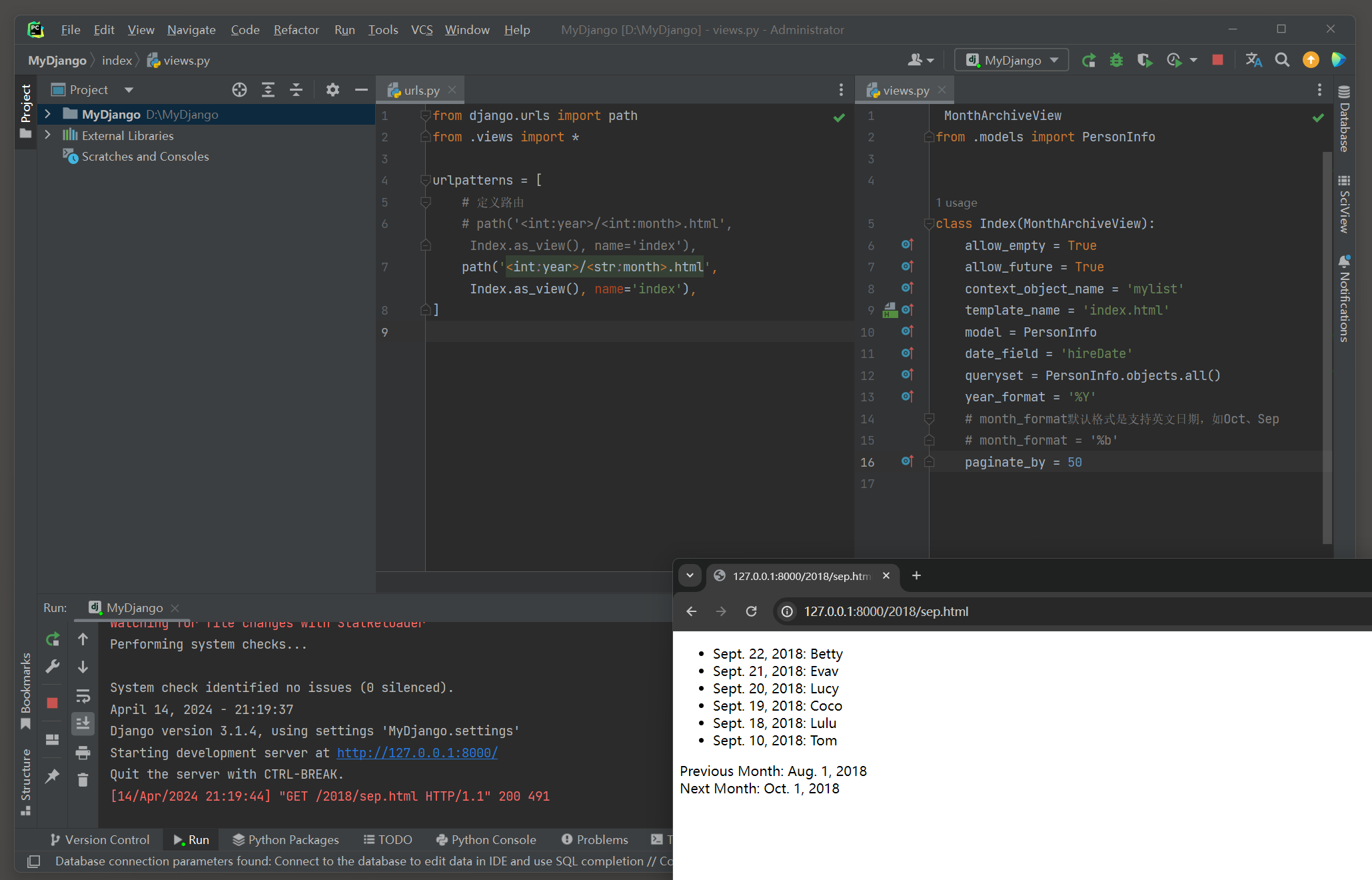
我们运行MyDjango项目 , 在浏览器上访问 : 127.0 .0 .1 : 8000 / 2018 / 9. html ,
Django对数据表index_personinfo的字段hireDate进行筛选 , 筛选条件为 2018 年 09 月份 , 符合条件的所有数据显示在网页上 , 如图 5 - 31 所示 .
图 5 - 31 运行结果
从图 5 - 31 看到 , 网页上显示的日期是以月 , 日 , 年的格式显示的 , 并且月份是以英文表示的 .
如果想让日期格式与数据库的日期格式相同 , 那么可以使用模板语法的过滤器date来转换日期格式 .
从路由index的变量month得知 , 该变量的数据类型可设为字符型 , 如果该变量改为字符型 , 那么视图类index无须设置属性month_format .
假设将路由变量month改为字符型并注释视图类index的属性month_format ,
重启运行MyDjango项目 , 在浏览器上访问 : 127.0 .0 .1 : 8000 / 2018 /sep.html , 网页显示的内容如下 .
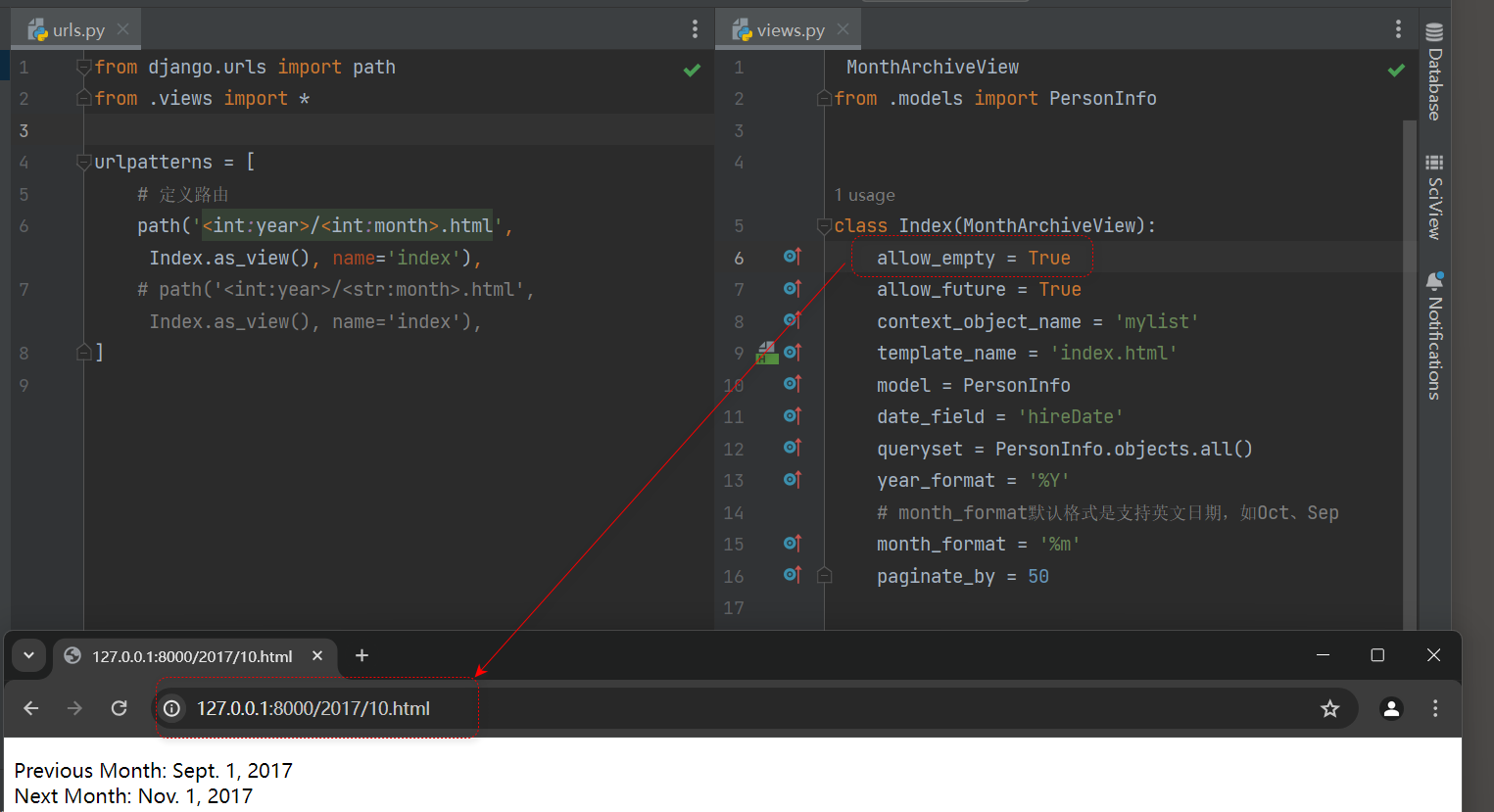
若想验证属性allow_empty和allow_future的作用 , 则可单独设置allow_empty的值 , 第一次设为True , 第二次设为False ,
并且每次都访问 : 127.0 .0 .1 : 8000 / 2017 / 10. html , 然后对比两次访问结果的差异即可 .
( allow_empty : 在模型中查询数据不存在的情况下是否显示页面 , 若为False并且数据不存在 , 则引发 404 异常 , 默认值为False . )
( 模板文件中 { % if previous_month % } . ) 和 { % if next_month % } 控制上下月份的渲染 .
数据库中最早的时间是 2018 / 7 月 , 访问这个地址的时候 , 不会显示上个月 ( 没有数据不允许访问 ) ,
数据库中最晚的时间是 2019 / 10 月 , 访问这个地址的时候 , 不会显示下个月 ( 没有数据不允许访问 ) . )
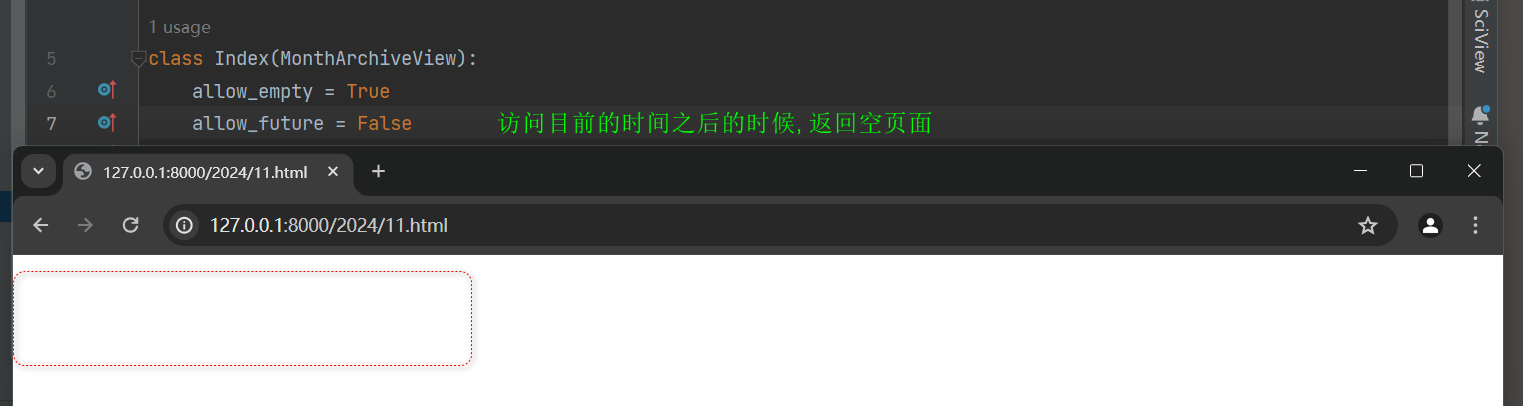
同理 , 属性allow_future的验证方式相同 , 但其访问的路由地址改为 : 127.0 .0 .1 : 8000 / 2019 / 10. html ( 使用当前时间 + 一个月测试 ) .
( allow_future : 这个属性决定用户是否可以通过 URL 访问未来的日期 , 默认为False , 则用户不能访问未来的日期 . )
综上所述 , 视图类MonthArchiveView是在列表视图ListView的基础上设置日期筛选功能的视图类 ,
日期筛选对象来自模型里的某个日期字段 , 筛选条件是由路由变量year和month提供的 ,
其中路由变量month的数据类型可选择为整型或字符型 , 不同的数据类型需要为month_format设置相应的属性值 .
在一年中 , 无论是平年还是闰年 , 一共有 52 周 , 而且每年同一个周数的日期是各不相同的 .
如果要对数据表的数据生成周报表 , 就需要根据当前年份的周数来计算相应的日期范围 , 这样可以大大降低开发效率 .
为此 , Django提供了视图类WeekArchiveView , 只需提供年份和周数即可在数据表里筛选相应的数据信息 .
视图类WeekArchiveView的继承过程在图 5 - 25 中已描述过了 , 整个设计共继承 10 个类 .
除了类WeekMixin之外 , 其他类的属性和方法已详细介绍过了 , 本小节不再重复讲述 , 我们只列举类WeekMixin定义的属性和方法 , 说明如下 :
● week_format : 由WeekMixin定义 , 默认值为 % U , 这是设置周数的计算方式 ,
可选值为 % W或 % U , 如果值为 % W , 周数就从星期一开始计算 , 如果值为 % U , 周数就从星期天开始计算 .
● week : 由WeekMixin定义 , 设置默认周数 , 如果没有设置属性值 , 就从路由变量week里获取 .
● get_week_format ( ) : 由WeekMixin定义 , 获取属性week_format的值 .
● get_week ( ) : 由WeekMixin定义 , 获取属性week的值 .
● get_next_week ( ) : 由WeekMixin定义 , 调用_get_next_week ( ) 来获取下一周的开始日期 .
● get_previous_week ( ) : 由WeekMixin定义 , 获取上一周的开始日期 .
● _get_next_week ( ) : 由WeekMixin定义的受保护方法 , 返回下一周的开始日期 .
● _get_current_week ( ) : 由WeekMixin定义的受保护方法 , 返回属性week所设周数的开始日期 .
● _get_weekday ( ) : 由WeekMixin定义的受保护方法 , 获取属性week所设周数的工作日 .
通过分析视图类WeekArchiveView的源码 , 我们对视图类WeekArchiveView有了大致的了解 .
下一步通过实例来讲述如何使用视图类WeekArchiveView , 它的使用方式与视图类MonthArchiveView非常相似 .
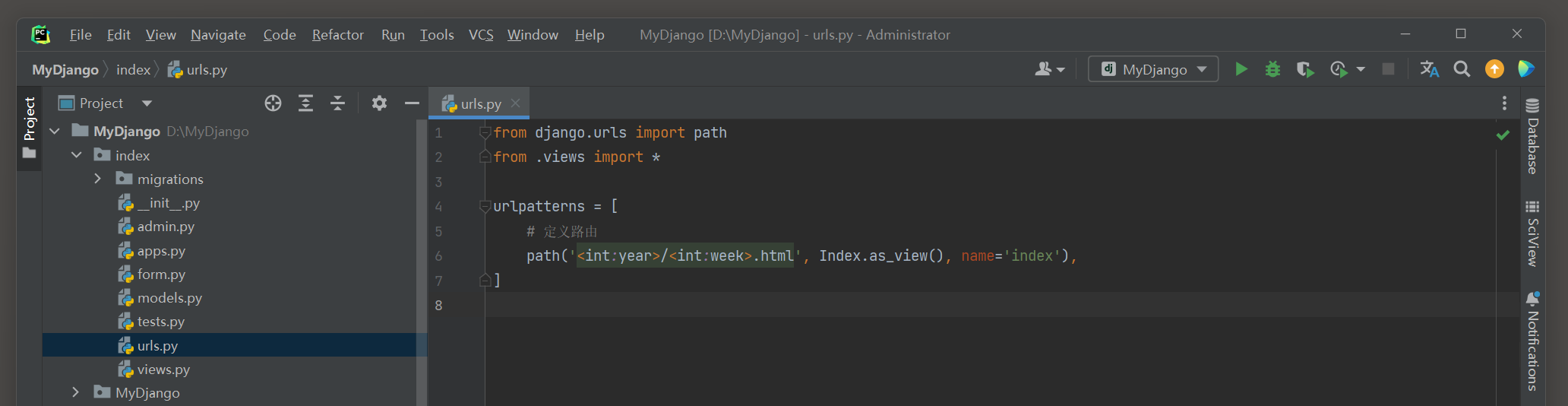
沿用 5.3 .1 小节的MyDjango项目 , 在index的urls . py , views . py和模板文件index . html中分别编写以下代码 :
from django. urls import path
from . views import *
urlpatterns = [
path( '<int:year>/<int:week>.html' , Index. as_view( ) , name= 'index' ) ,
]
from django. views. generic. dates import WeekArchiveView
from . models import PersonInfo
class Index ( WeekArchiveView) :
allow_empty = True
allow_future = True
context_object_name = 'mylist'
template_name = 'index.html'
model = PersonInfo
date_field = 'hireDate'
queryset = PersonInfo. objects. all ( )
year_format = '%Y'
week_format = '%W'
paginate_by = 50
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> < body> < ul> < li> </ li> </ ul> < p> < br> </ p> </ body> </ html>
路由index定义路由变量year和week , 它们只能支持整型的数据格式 , 并且变量名是固定的 ,
否则视图类WeekArchiveView无法从路由变量里获取年份和周数 .
视图类index继承父类WeekArchiveView , 它共设置了 10 个属性 ,
每个属性的设置与 5.3 .1 小节的视图类index大致相同 , 唯独将属性month_format改为week_format .
模板文件index . html的模板上下文也与视图类MonthArchiveView提供的模板上下文相似 ,
只不过上一周和下一周的上下文改为previous_week和next_week .
综上所述 , 视图类WeekArchiveView和MonthArchiveView在使用上存在相似之处 ,
也就是说 , 只要熟练掌握某个日期视图类的使用方法 , 其他日期视图类的使用也能轻易地掌握 .
数据表index_personinfo的大部分数据集中在 2018 年 9 月 , 这个日期的周数为 38.
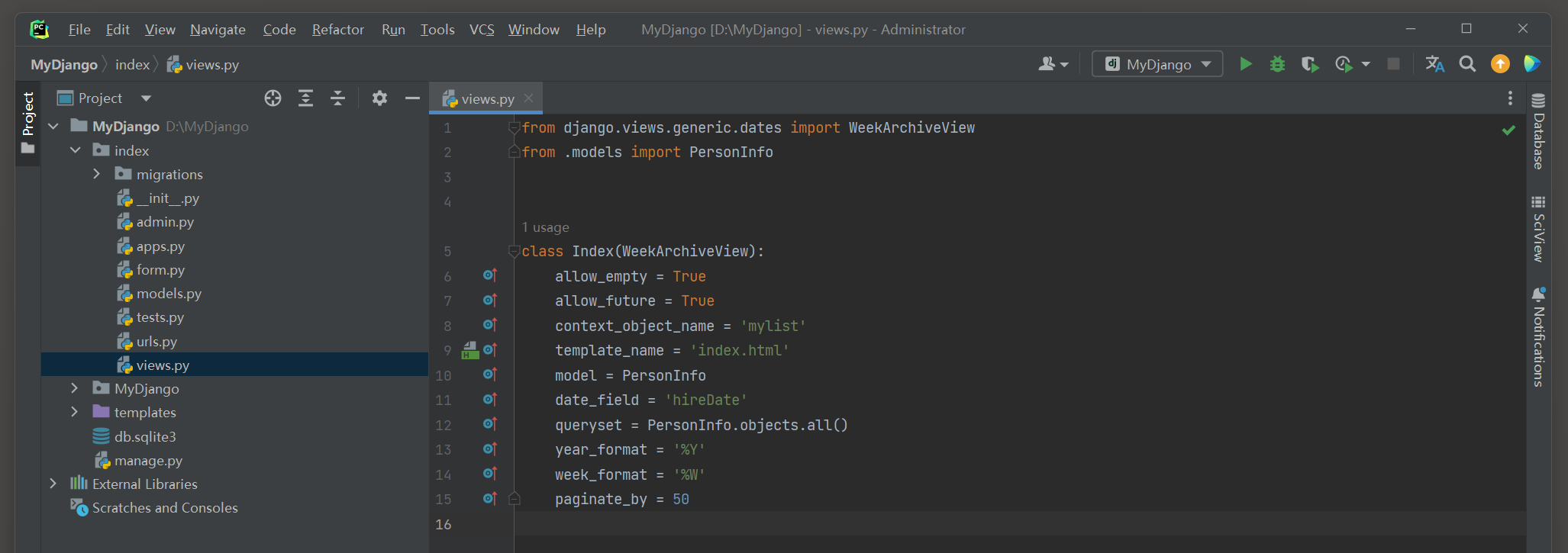
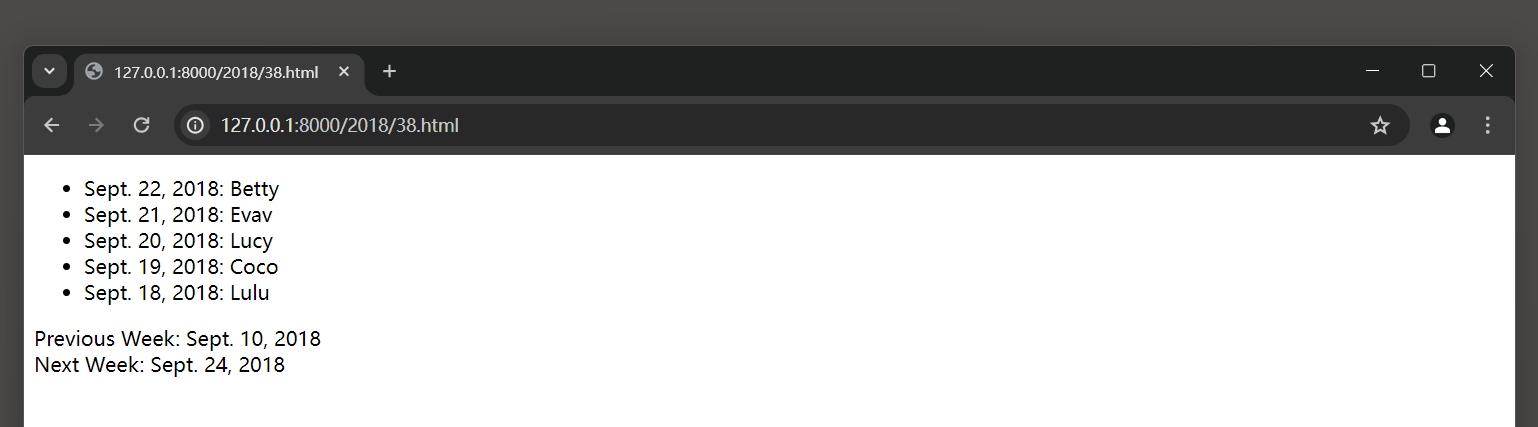
运行MyDjango项目 , 在浏览器上访问 : 127.0 .0 .1 : 8000 / 2018 / 38. html ,
Django将日期从 2018 - 09 - 18 至 2018 - 09 - 22 的数据显示在网页上 , 如图 5 - 32 所示 .
图 5 - 32 运行结果
Web开发是一项无聊而且单调的工作 , 特别是在视图编写功能方面更为显著 .
为了减少这类痛苦 , Django植入了视图类这一功能 , 该功能封装了视图开发常用的代码和模式 ,
可以在无须编写大量代码的情况下 , 快速完成数据视图的开发 , 这种以类的形式实现响应与请求处理称为CBV .
视图类是通过定义和声明类的形式实现的 , 根据用途划分 3 部分 : 数据显示视图 , 数据操作视图和日期筛选视图 .
数据显示视图是将后台的数据展示网页上 , 数据主要来自模型 , 一共定义了 4 个视图类 ,
分别是RedirectView , TemplateView , ListView和DetailView , 说明如下 :
● RedirectView用于实现HTTP重定向 , 默认情况下只定义GET请求的处理方法 .
● TemplateView是视图类的基础视图 , 可将数据传递给HTML模板 , 默认情况下只定义GET请求的处理方法 .
● ListView是在TemplateView的基础上将数据以列表显示 , 通常将某个数据表的数据以列表表示 .
● DetailView是在TemplateView的基础上将数据详细显示 , 通常获取数据表的单条数据 .
数据操作视图是对模型进行操作 , 如增 , 删 , 改 , 从而实现Django与数据库的数据交互 .
数据操作视图有 4 个视图类 , 分别是FormView , CreateView , UpdateView和DeleteView , 说明如下 :
● FormView视图类使用内置的表单功能 , 通过表单实现数据验证 , 响应输出等功能 , 用于显示表单数据 .
● CreateView实现模型的数据新增功能 , 通过内置的表单功能实现数据新增 .
● UpdateView实现模型的数据修改功能 , 通过内置的表单功能实现数据修改 .
● DeleteView实现模型的数据删除功能 , 通过内置的表单功能实现数据删除 .
日期筛选视图是根据模型里的某个日期字段进行数据筛选 , 然后将符合结果的数据以一定的形式显示在网页上 .
简单来说 , 就是在列表视图ListView或详细视图DetailView的基础上增加日期筛选所实现的视图类 .
它一共定义了 7 个日期视图类 , 其说明如下 :
● ArchiveIndexView是将数据表所有的数据以某个日期字段的降序方式进行排序显示 .
● YearArchiveView是在数据表筛选某个日期字段某年的所有数据 , 并默认以升序的方式排序显示 , 年份的筛选范围由路由变量提供 .
● MonthArchiveView是在数据表筛选某个日期字段某年某月的所有数据 , 并默认以升序的方式排序显示 ,
年份和月份的筛选范围都是由路由变量提供的 .
● WeekArchiveView是在数据表筛选某个日期字段某年某周的所有数据 ,
总周数是将一年的总天数除以 7 所得的 , 数据默认以升序的方式排序显示 , 年份和周数的筛选范围都是由路由变量提供的 .
● DayArchiveView是对数据表的某个日期字段精准筛选到某年某月某天 ,
将符合条件的数据以升序的方式排序显示 , 年份 , 月份和天数都是由路由变量提供的 .
● TodayArchiveView是在视图类DayArchiveView的基础上进行封装处理 ,
它将数据表某个日期字段的筛选条件设为当天时间 , 符合条件的数据以升序的方式排序显示 .
● DateDetailView用于查询某年某月某日某条数据的详细信息 ,
它在视图类DetailView的基础上增加日期筛选功能 , 筛选条件主要有年份 , 月份 , 天数和某个模型字段 ,
其中某个模型字段必须具有唯一性 , 才能确保查询的数据具有唯一性 .